
The Map() itself is very simple. Here's the Python code:
def RemoveOldFeedEntryRecordPropertiesMapper(feed_entry_record):
OLD_PROPERTIES = ('entry_id_hash', 'entry_id')
for name in OLD_PROPERTIES:
if hasattr(feed_entry_record, name):
delattr(feed_entry_record, name)
yield op.db.Put(feed_entry_record)
This will remove some wasteful properties and write the entity back to the Datastore and update its indexes, many of which I've removed (which is a big part of why I get a storage savings; more detail here). Importantly, each map call results in a Datastore write; anyone who has run big MapReduce jobs (on Hadoop or otherwise) will tell you that writes (and their poor throughput) is often what kills offline processing performance.I ran my job on 16 shards, meaning 16 CPU cores were in use at a time in parallel. My results surprised me! Here are the important stats:
- Elapsed time: 8 days, 12:59:25
- mapper_calls: 1533270409 (2077.7/sec avg.)
In terms of cost, the map job only doubled the daily price of running Google's Hub on App Engine. That's awesome, especially considering the amount of low-hanging-optimization fruit (mmm... delicious) still present in the Mapper framework. I expect us to deliver an order of magnitude of efficiency and performance improvements for the framework.
After three+ years of working on App Engine, it's kind of surprising to me that I'm now more excited about its future than ever before. I've known App Engine is special since the beginning (eg: no config, easiest-ever deployment, auto-scaling). But where it's headed now is more advanced than any other cluster or batch-data system I have used or read about.
Here's the Datastore statistics page before I ran my job:
| Total Number of FeedEntryRecord Entities: | Average Size of Entity: |
|---|---|
| 1,433,233,338 | 411 Bytes |
Storage Space by Property Type
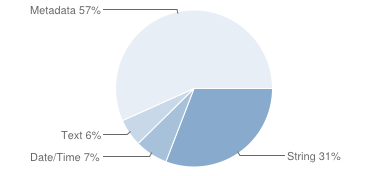
Storage Space by Entity Kind

| Property | Type | Size |
|---|---|---|
entry_content_hash | String | 88 GBytes (16% of the entity) |
entry_id_hash | String | 81 GBytes (15% of the entity) |
update_time | Date/Time | 37 GBytes (7% of the entity) |
entry_id | Text | 31 GBytes (6% of the entity) |
topic | Text | 1 KBytes (0% of the entity) |
topic_hash | String | 1 KBytes (0% of the entity) |
Metadata | 312 GBytes (57% of the entity) |
Here it is after (modulo time and data growth):
| Total Number of FeedEntryRecord Entities: | Average Size of Entity: |
|---|---|
| 1,756,534,609 | 325 Bytes |
Storage Space by Property Type

Storage Space by Entity Kind

| Property | Type | Size |
|---|---|---|
entry_content_hash | String | 108 GBytes (20% of the entity) |
update_time | Date/Time | 46 GBytes (9% of the entity) |
entry_id_hash | String | 14 MBytes (0% of the entity) |
entry_id | Text | 2 MBytes (0% of the entity) |
Metadata | 378 GBytes (71% of the entity) |