
I started a new YouTube channel called Worst Practices in Software Development. The premise: We're all exhausted of hearing everyone's "best" practices in software development. What are your worst practices? The goal is to learn about how people actually write code. I have a theory that nearly all of the horrible things that everyone tells you to avoid in programming are precisely the best way to build software.
Here are some example episodes to give you a taste of what it's like:
You can also subscribe to the audio-only version on Apple Podcasts, Spotify, and Google Podcasts.
Thanks for watching and/or listening!
I'm Brett Slatkin and this is where I write about programming and related topics. You can contact me here or view my projects.
06 May 2023
04 May 2023
Advice for computer science students
I recently received this question and thought it might be useful to publish my reply:
It seems to me that the judgement of software engineers has become more valuable over the past 20 years because software is more ubiquitous than ever. Consider this proxy for the importance of software: In 2003 only 61% of the US adult population was online. Today it's 93%, thanks in part to the popularity of smart phones and mobile apps, streaming services like Netflix, online shopping like Amazon, etc. Globally, the prevalence of internet usage has grown from 12% to 60% of the population in the same time period, and it continues to grow rapidly. I think it's safe to assume that software will become an even more critical part of our society over time, not less.
These new code-capable AI/ML models, such as GitHub Copilot and ChatGPT, appear to be helpful tools for software development, much like prior inventions such as high-level languages, WYSIWYG interface builders, open source frameworks, etc. They have the potential to enhance your ability to be productive. If you are more productive, presumably an employer paying you gets a higher return on their investment. With a higher ROI, they can choose to either (A) do the same software projects with fewer resources (cost cutting), or (B) take on larger and more complex software engineering projects (keep costs flat or increase them).
Given the growing criticality of software, I'm optimistic that many employers will choose (B) in the long term. These new AI/ML tools might also help "non-professional programmers" — a growing part of the Python ecosystem — become more capable and self-sufficient. But again, I think this translates to more ROI on software development projects and growth instead of stagnation. I'll be truly worried when it appears we've reached the saturation point of software: all the programs that need to exist have been written and everything left to do is maintenance. In some fields it seems like we're already there. In most others we've barely even started.
Ultimately you need to ask yourself if computer programming is a job you want to be doing. It's a very personal decision.
"I'm a CS student... I've been losing faith in any kind of bright future for me and my peers consistently over the past few months... Please, tell me what your honest take on this ChatGPT situation is."
It seems to me that the judgement of software engineers has become more valuable over the past 20 years because software is more ubiquitous than ever. Consider this proxy for the importance of software: In 2003 only 61% of the US adult population was online. Today it's 93%, thanks in part to the popularity of smart phones and mobile apps, streaming services like Netflix, online shopping like Amazon, etc. Globally, the prevalence of internet usage has grown from 12% to 60% of the population in the same time period, and it continues to grow rapidly. I think it's safe to assume that software will become an even more critical part of our society over time, not less.
These new code-capable AI/ML models, such as GitHub Copilot and ChatGPT, appear to be helpful tools for software development, much like prior inventions such as high-level languages, WYSIWYG interface builders, open source frameworks, etc. They have the potential to enhance your ability to be productive. If you are more productive, presumably an employer paying you gets a higher return on their investment. With a higher ROI, they can choose to either (A) do the same software projects with fewer resources (cost cutting), or (B) take on larger and more complex software engineering projects (keep costs flat or increase them).
Given the growing criticality of software, I'm optimistic that many employers will choose (B) in the long term. These new AI/ML tools might also help "non-professional programmers" — a growing part of the Python ecosystem — become more capable and self-sufficient. But again, I think this translates to more ROI on software development projects and growth instead of stagnation. I'll be truly worried when it appears we've reached the saturation point of software: all the programs that need to exist have been written and everything left to do is maintenance. In some fields it seems like we're already there. In most others we've barely even started.
Ultimately you need to ask yourself if computer programming is a job you want to be doing. It's a very personal decision.
04 March 2023
Why am I building a new functional programming language?
I once asked Guido van Rossum (the creator of Python, and my former teammate working on Google App Engine) what he thought of functional programming languages. I had told him about my recent frustration in trying to learn Haskell, and my skepticism from using Lisp. His reply was eye-opening: He spoke of the potential for functional languages to provide a significant, intrinsic advantage when it comes to parallel computing. I had never observed this myself, so I found the concept intriguing and it stuck with me.
Since that conversation, I spent many years building big data processing systems that leveraged functional concepts (such as Map Reduce and Flume). I also built high-scale, low-latency, globally distributed systems, and felt the pain of shared state, replication delays, idempotent operations, etc. Although our tools have continued to improve (such as golang), it's still too difficult to solve these types of problems, even for experienced programmers. This has made me wonder if perhaps the issue is not the quality of the languages, libraries, and ecosystems, but something more fundamental like the predominant paradigm (imperative programming).
If that were true, you'd expect that the many existing functional programming languages would have already satisfied this need. But in my opinion, they haven't. For example, it's hard to reconcile how the users of these functional languages can be so passionate about them, while non-users find them so perplexing. Why is the gap between these two perspectives so large? My conclusion is that there are major, well-justified reasons for why people strongly dislike functional languages. The hypothesis I aim to test with a new programming language is: By making different tradeoffs, these issues can be mitigated and a more broadly-appealing functional language can be built. With such a language, I hope that the true promise of functional programming for parallel computing can be widely realized.
This opportunity is not limited to the server-side and distributed systems. The future of all computing will leverage more parallelism. The machines we have on our desktops, in our laps, and in our hands include an increasing number of cores and heterogeneous accelerators. They function more like a micro-datacenter than a computer of old. Network connectivity has improved so much that the boundaries between datacenters, edges, and devices continue to blur. So whether you're trying to build a mobile app or optimize a scientific workload, parallelism is and will continue to be the most critical aspect of programming.
Since that conversation, I spent many years building big data processing systems that leveraged functional concepts (such as Map Reduce and Flume). I also built high-scale, low-latency, globally distributed systems, and felt the pain of shared state, replication delays, idempotent operations, etc. Although our tools have continued to improve (such as golang), it's still too difficult to solve these types of problems, even for experienced programmers. This has made me wonder if perhaps the issue is not the quality of the languages, libraries, and ecosystems, but something more fundamental like the predominant paradigm (imperative programming).
If that were true, you'd expect that the many existing functional programming languages would have already satisfied this need. But in my opinion, they haven't. For example, it's hard to reconcile how the users of these functional languages can be so passionate about them, while non-users find them so perplexing. Why is the gap between these two perspectives so large? My conclusion is that there are major, well-justified reasons for why people strongly dislike functional languages. The hypothesis I aim to test with a new programming language is: By making different tradeoffs, these issues can be mitigated and a more broadly-appealing functional language can be built. With such a language, I hope that the true promise of functional programming for parallel computing can be widely realized.
This opportunity is not limited to the server-side and distributed systems. The future of all computing will leverage more parallelism. The machines we have on our desktops, in our laps, and in our hands include an increasing number of cores and heterogeneous accelerators. They function more like a micro-datacenter than a computer of old. Network connectivity has improved so much that the boundaries between datacenters, edges, and devices continue to blur. So whether you're trying to build a mobile app or optimize a scientific workload, parallelism is and will continue to be the most critical aspect of programming.
22 November 2022
The case for dynamic, functional programming
This question has been answered many times before, but it bears repeating: Why do people like using dynamic languages? One common compelling reason is that dynamic languages like Python only require you to learn a single tool in order to use them well. In contrast, to use modern C++ you need to understand five separate languages:
With Python it's much easier to become proficient and remember everything you need to know. That translates to more time being productive writing code instead of reading documentation. Code that runs at compile/import time follows the same rules as code running at execution time. Instead of a separate templating system, the language supports meta-programming using the same constructs as normal execution. Module importing is built-in, so build systems aren't necessary (unless you must use a custom C-extension module). There is no static type system, so you don't need to "emulate the compiler" in your head to reason about compilation errors.
That said, Python is an imperative language, which means you still need to "emulate the state machine" to reason about how values change over time. For example, when you read a function's source code, it could refer to variables outside of its scope (such as globals or the fields of an object). That means you need to think to yourself about how those variables might affect your program's behavior by making assumptions about their values.
As a concrete example, take this stateful, imperative code:
These questions might come to mind:
In contrast, none of these questions arise in this purely functional code because all of the inputs and outputs are of known quality and the relationship between state and time (i.e., program execution order) is explicit:
Beginner programmers learn that they should avoid global variables because of how their hidden state and unintended coupling causes programs to be difficult to understand and debug. By the same reasoning, isn't it possible to conclude that all state that isn't strictly necessary should be avoided? Then why are we still writing such stateful programs these days?
Similar to how dynamic languages don't require you to "emulate the compiler" in your head, purely functional languages don't require you to "emulate the state machine". Functional languages reduce the need to reason about time and state changes. When you read such a program, you can trace the assignment of every variable and be confident that it won't be changed by an external force. It's all right there for you to see. Imperative languages require you to think about two modes of computation (stateless and stateful). Purely functional programs only require the former and thus should be easier to understand.
If you're a fan of dynamic languages because of their simplicity, then you should also be a fan of functional programming for furthering that goal by removing the need for thinking about state. Theoretically, functional programs should: have fewer bugs, be easier to optimize for performance, allow you to add features more quickly, achieve the same outcome with less effort, require less time to get familiarized with a new codebase, etc. With a dynamic, functional language you could enjoy all of this simplicity.
But you don't even need that to benefit from this perspective today! You can adopt the techniques of functional programming right now in your favorite language (such as Python, used above). What's important is your mindset and how you approach problems, minimizing state and maximizing clarity in the code you write.
- The preprocessor
- The C++ type system
- The C++ template language
- The C++ language itself
- And whatever tool you're using for builds, such as make
With Python it's much easier to become proficient and remember everything you need to know. That translates to more time being productive writing code instead of reading documentation. Code that runs at compile/import time follows the same rules as code running at execution time. Instead of a separate templating system, the language supports meta-programming using the same constructs as normal execution. Module importing is built-in, so build systems aren't necessary (unless you must use a custom C-extension module). There is no static type system, so you don't need to "emulate the compiler" in your head to reason about compilation errors.
That said, Python is an imperative language, which means you still need to "emulate the state machine" to reason about how values change over time. For example, when you read a function's source code, it could refer to variables outside of its scope (such as globals or the fields of an object). That means you need to think to yourself about how those variables might affect your program's behavior by making assumptions about their values.
As a concrete example, take this stateful, imperative code:
class TimeElapsed(Exception):
pass
class MyTimer:
def __init__(self, threshold):
self.threshold = threshold
self.count = 0
def increment(self):
self.count += 1
if self.count >= self.threshold:
raise TimeElapsed
timer = MyTimer(3)
timer.increment()
timer.increment()
timer.increment() # Raises
These questions might come to mind:
- Is
self.countever modified outside ofincrement, and will that codepath properly raise the timer exception? - Is
self.countreset to zero separately or should I reset it when raising the timer exception? - Is
self.thresholdconstant or can it be changed, and will the timer exception be raised properly when it's changed?
In contrast, none of these questions arise in this purely functional code because all of the inputs and outputs are of known quality and the relationship between state and time (i.e., program execution order) is explicit:
def timer(count):
if count <= 0:
raise TimeElapsed
return count - 1
step1 = timer(3)
step2 = timer(step1)
step3 = timer(step2)
step4 = timer(step3) # Raises
Beginner programmers learn that they should avoid global variables because of how their hidden state and unintended coupling causes programs to be difficult to understand and debug. By the same reasoning, isn't it possible to conclude that all state that isn't strictly necessary should be avoided? Then why are we still writing such stateful programs these days?
Similar to how dynamic languages don't require you to "emulate the compiler" in your head, purely functional languages don't require you to "emulate the state machine". Functional languages reduce the need to reason about time and state changes. When you read such a program, you can trace the assignment of every variable and be confident that it won't be changed by an external force. It's all right there for you to see. Imperative languages require you to think about two modes of computation (stateless and stateful). Purely functional programs only require the former and thus should be easier to understand.
If you're a fan of dynamic languages because of their simplicity, then you should also be a fan of functional programming for furthering that goal by removing the need for thinking about state. Theoretically, functional programs should: have fewer bugs, be easier to optimize for performance, allow you to add features more quickly, achieve the same outcome with less effort, require less time to get familiarized with a new codebase, etc. With a dynamic, functional language you could enjoy all of this simplicity.
But you don't even need that to benefit from this perspective today! You can adopt the techniques of functional programming right now in your favorite language (such as Python, used above). What's important is your mindset and how you approach problems, minimizing state and maximizing clarity in the code you write.
19 April 2022
Old programmers joke
(Via Vint Cerf)
1st programmer: Back in my day we didn't have fancy high-level languages, we had to use assembly.
2nd programmer: Pssh — assembly? What a cakewalk. In my day we could only write programs with zeros and ones!
3rd programmer: You had ones?!
25 June 2021


28 October 2019
I wrote a new edition of my book
This week I announced that Effective Python: Second Edition is now available for preorder. It ships in mid-November this year (mere weeks away!). The new edition is nearly twice the length of the previous one, and substantially revises all of the items of advice in addition to providing 30+ more. I hope you like it!

This second edition was easier to write in some ways and much harder in others. It was easier because I'd written a book before. I know how to put words on the page everyday and keep up the pace of writing. I've been through the whole process of delivering drafts, incorporating technical reviewer feedback, working with various editors, etc. And I was able to reuse the literate programming toolchain that I built in order to write the first edition, which saved a lot of time and allowed me to focus on the words and code instead of the process.
What was most difficult about writing the second edition of the book was how much Python has evolved in the interim. The first edition of the book covered Python 2.7 and Python 3.4. Python 2 will be dead and deprecated in the next 3 months, so I needed to remove all mention of it. For Python 3, there were major changes to the language in versions 3.5 (async/await, unpacking generalizations, type hints), 3.6 (f-strings, __init_subclass__, async generators/comprehensions, variable annotations), 3.7 (asyncio improvements, breakpoint), and this month with 3.8's release (assignment expressions, positional-only arguments).
Each time a new version of Python 3 came out, I had to gain experience with its features and reconsider my previous advice. For example, one of the items I'm most proud of in the first edition ("Consider Coroutines to Run Many Functions Concurrently") is now obsolete. My advice in the second edition is to completely avoid these features of generators (send and throw) in favor of the new async/await syntax from 3.5. However, I'm not sure I would have reached that conclusion had it not been for the improvements to the asyncio module made in 3.7.
The same type of interdependent changes seemed necessary for almost all items of advice in the book, which meant I had to potentially redo everything. I find that the hardest part of writing is editing (e.g., "If I had more time, I would have written a shorter letter."), so this was quite a challenge. I repeatedly delayed the start of my writing sprint so I could learn more about the evolving features and wait for them to mature. Luckily, I felt that the language finally stabilized with version 3.7, and 3.8 presented usability improvements that are worthwhile instead of major structural changes. Thus, the new edition is done and here we are.
Today's Python 3 is a very different language than version 3.0 that was released over 10 years ago. I wonder how the language will continue to grow over the coming years. There are some especially exciting efforts going on related to CPU performance, such as PEP 554 (subinterpreters) and tools like the Mypy to Python C Extension Compiler. I look forward to what comes next (Python 4?), and the potential opportunity to write a third edition of the book (many years from now).
This second edition was easier to write in some ways and much harder in others. It was easier because I'd written a book before. I know how to put words on the page everyday and keep up the pace of writing. I've been through the whole process of delivering drafts, incorporating technical reviewer feedback, working with various editors, etc. And I was able to reuse the literate programming toolchain that I built in order to write the first edition, which saved a lot of time and allowed me to focus on the words and code instead of the process.
What was most difficult about writing the second edition of the book was how much Python has evolved in the interim. The first edition of the book covered Python 2.7 and Python 3.4. Python 2 will be dead and deprecated in the next 3 months, so I needed to remove all mention of it. For Python 3, there were major changes to the language in versions 3.5 (async/await, unpacking generalizations, type hints), 3.6 (f-strings, __init_subclass__, async generators/comprehensions, variable annotations), 3.7 (asyncio improvements, breakpoint), and this month with 3.8's release (assignment expressions, positional-only arguments).
Each time a new version of Python 3 came out, I had to gain experience with its features and reconsider my previous advice. For example, one of the items I'm most proud of in the first edition ("Consider Coroutines to Run Many Functions Concurrently") is now obsolete. My advice in the second edition is to completely avoid these features of generators (send and throw) in favor of the new async/await syntax from 3.5. However, I'm not sure I would have reached that conclusion had it not been for the improvements to the asyncio module made in 3.7.
The same type of interdependent changes seemed necessary for almost all items of advice in the book, which meant I had to potentially redo everything. I find that the hardest part of writing is editing (e.g., "If I had more time, I would have written a shorter letter."), so this was quite a challenge. I repeatedly delayed the start of my writing sprint so I could learn more about the evolving features and wait for them to mature. Luckily, I felt that the language finally stabilized with version 3.7, and 3.8 presented usability improvements that are worthwhile instead of major structural changes. Thus, the new edition is done and here we are.
Today's Python 3 is a very different language than version 3.0 that was released over 10 years ago. I wonder how the language will continue to grow over the coming years. There are some especially exciting efforts going on related to CPU performance, such as PEP 554 (subinterpreters) and tools like the Mypy to Python C Extension Compiler. I look forward to what comes next (Python 4?), and the potential opportunity to write a third edition of the book (many years from now).
25 August 2018
Probabilistic programming
After many years of using only frequentist methods for survey statistics, I've also been spending a lot of time lately learning about and applying Bayesian methods (specifically for A/B testing). It's a bit of a culture shock for me, given that the Frequentists and the Bayesians don't see reality the same way. But I'm having a lot of fun looking at the world through a new lens. For example, here's the diagnostic output from a model I built recently using the PyMC3 library:
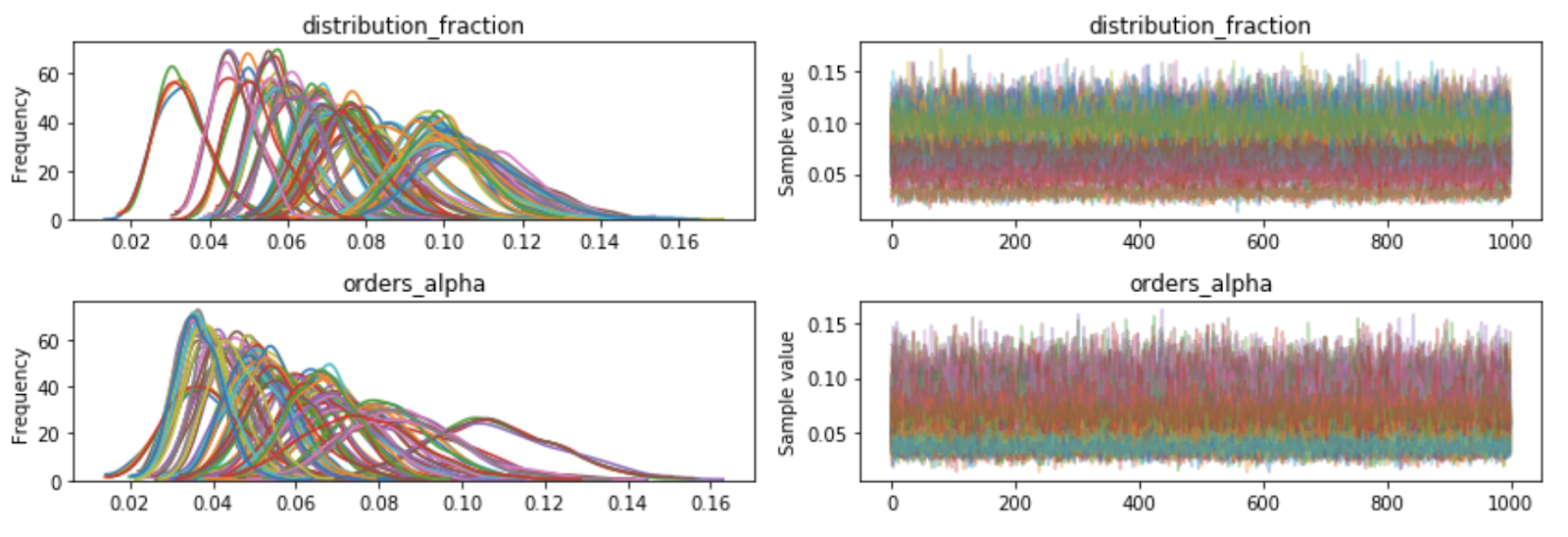
There is some great info out there about algorithms like MCMC that are used for Bayesian statistical inference, and it's pretty approachable if you have a basic knowledge of statistics. What's interesting is that these methods build on the same math (gradients, matrix calculus, etc) that you'd need to understand for machine learning. Why not learn both while you're at it?
There's also the developing area of Bayesian deep learning, where the concepts of Bayesian inference and deep learning are brought together to create models that provide not just predictions but also the uncertainty that the model has in them. This is especially interesting to me because I've found it difficult to successfully apply ML to survey statistics: it's critical to provide confidence intervals for survey data and most ML tools don't support them without dubious methods.
So I'm excited about libraries like Edward (Bayesian tools built on TensorFlow), which have the potential to make this field a lot more accessible and scalable. It appears that Edward is being integrated into TensorFlow itself. This could be awesome because building on TensorFlow means you might be able to take advantage of things like TPUs, which would speed up these Bayesian algorithms significantly (in comparison to Stan, the de facto standard tool for Bayesian inference, which relies primarily on CPU execution).
Anyways, though I'm definitely late to this party, I'm still happy to be here.
There is some great info out there about algorithms like MCMC that are used for Bayesian statistical inference, and it's pretty approachable if you have a basic knowledge of statistics. What's interesting is that these methods build on the same math (gradients, matrix calculus, etc) that you'd need to understand for machine learning. Why not learn both while you're at it?
There's also the developing area of Bayesian deep learning, where the concepts of Bayesian inference and deep learning are brought together to create models that provide not just predictions but also the uncertainty that the model has in them. This is especially interesting to me because I've found it difficult to successfully apply ML to survey statistics: it's critical to provide confidence intervals for survey data and most ML tools don't support them without dubious methods.
So I'm excited about libraries like Edward (Bayesian tools built on TensorFlow), which have the potential to make this field a lot more accessible and scalable. It appears that Edward is being integrated into TensorFlow itself. This could be awesome because building on TensorFlow means you might be able to take advantage of things like TPUs, which would speed up these Bayesian algorithms significantly (in comparison to Stan, the de facto standard tool for Bayesian inference, which relies primarily on CPU execution).
Anyways, though I'm definitely late to this party, I'm still happy to be here.
22 January 2018
Worrying
The most valuable skill you can have as a junior developer is the ability to worry.
Advice I've often heard from senior developers is to "delegate responsibilities, not tasks". The idea is that you ask a junior teammate to take ownership of delivering an outcome without being specific about how to do it. This gives them autonomy and flexibility, providing enough room for them to come up with a creative solution on their own. They'll also learn a lot by pushing their own boundaries in the process. If you only delegate tasks, you'll artificially limit what your teammate can do and prevent them from achieving a truly excellent result.
Sounds great, but concretely how do you go about delegating responsibilities? Nobody explains that part. Sometimes it seems obvious, like asking a teammate to "reduce the number of user-visible HTTP 500s by 90%" without any guidance. The result you're looking for is quantifiable. There are many ways to do it (e.g., better tests, more logs, profiling). Asking someone to take responsibility for improving such a metric is straightforward.
But important goals are usually much more amorphous, like "make sure our most valuable customer is happy". There are metrics in there, sure, but the hardest parts are addressing the human factors: Is the customer confident in our product? Are they satisfied with our team's level of attentiveness? Does our roadmap align with their long-term needs? Are they considering switching to another provider? You can't easily quantify the answers to these questions or measure how software development causes incremental improvements to them.
How do you ask someone to be responsible for such an open-ended goal?
My approach is to ask them to "worry on my behalf" about the goal. Worrying is anticipating problems before they happen. Worrying is not taking for granted that everything will continue as planned. Worrying is finding and fixing bugs before anyone else notices. Worrying is being pessimistic about the quality of our codebase and the stability of our infrastructure. Worrying is identifying and mitigating risks in advance. Worrying is verifying the strength of relationships with more communication. Worrying on my behalf is considering everything that might go wrong so I don't have to. This is what I expect from people who take on responsibilities.
Delegating worries transforms my role as the technical lead into one where I'm listening to my teammates to figure out what needs to happen, instead of the other way around. I still ask many questions to fully understand issues and their severity. Then I reprioritize what our team will do across all of the various worries that comprise our project. Running a team this way reduces my responsibilities to 1) are the worriers I've delegated to worrying enough? and 2) is there anything new that I should be worried about? It's a more efficient use of everyone's time.
Advice I've often heard from senior developers is to "delegate responsibilities, not tasks". The idea is that you ask a junior teammate to take ownership of delivering an outcome without being specific about how to do it. This gives them autonomy and flexibility, providing enough room for them to come up with a creative solution on their own. They'll also learn a lot by pushing their own boundaries in the process. If you only delegate tasks, you'll artificially limit what your teammate can do and prevent them from achieving a truly excellent result.
Sounds great, but concretely how do you go about delegating responsibilities? Nobody explains that part. Sometimes it seems obvious, like asking a teammate to "reduce the number of user-visible HTTP 500s by 90%" without any guidance. The result you're looking for is quantifiable. There are many ways to do it (e.g., better tests, more logs, profiling). Asking someone to take responsibility for improving such a metric is straightforward.
But important goals are usually much more amorphous, like "make sure our most valuable customer is happy". There are metrics in there, sure, but the hardest parts are addressing the human factors: Is the customer confident in our product? Are they satisfied with our team's level of attentiveness? Does our roadmap align with their long-term needs? Are they considering switching to another provider? You can't easily quantify the answers to these questions or measure how software development causes incremental improvements to them.
How do you ask someone to be responsible for such an open-ended goal?
My approach is to ask them to "worry on my behalf" about the goal. Worrying is anticipating problems before they happen. Worrying is not taking for granted that everything will continue as planned. Worrying is finding and fixing bugs before anyone else notices. Worrying is being pessimistic about the quality of our codebase and the stability of our infrastructure. Worrying is identifying and mitigating risks in advance. Worrying is verifying the strength of relationships with more communication. Worrying on my behalf is considering everything that might go wrong so I don't have to. This is what I expect from people who take on responsibilities.
Delegating worries transforms my role as the technical lead into one where I'm listening to my teammates to figure out what needs to happen, instead of the other way around. I still ask many questions to fully understand issues and their severity. Then I reprioritize what our team will do across all of the various worries that comprise our project. Running a team this way reduces my responsibilities to 1) are the worriers I've delegated to worrying enough? and 2) is there anything new that I should be worried about? It's a more efficient use of everyone's time.
11 November 2017
Baby Names
A dataset I've been playing around with recently is the list of names from the US Social Security Administration, which goes from the year 1880 through 2016. I loaded the data into BigQuery and then made this visualization using Data Studio. It's been interesting looking up the names of my friends and family to see just how popular their names are now versus the time they were born. Here are some of the most interesting patterns that I've found in the data:
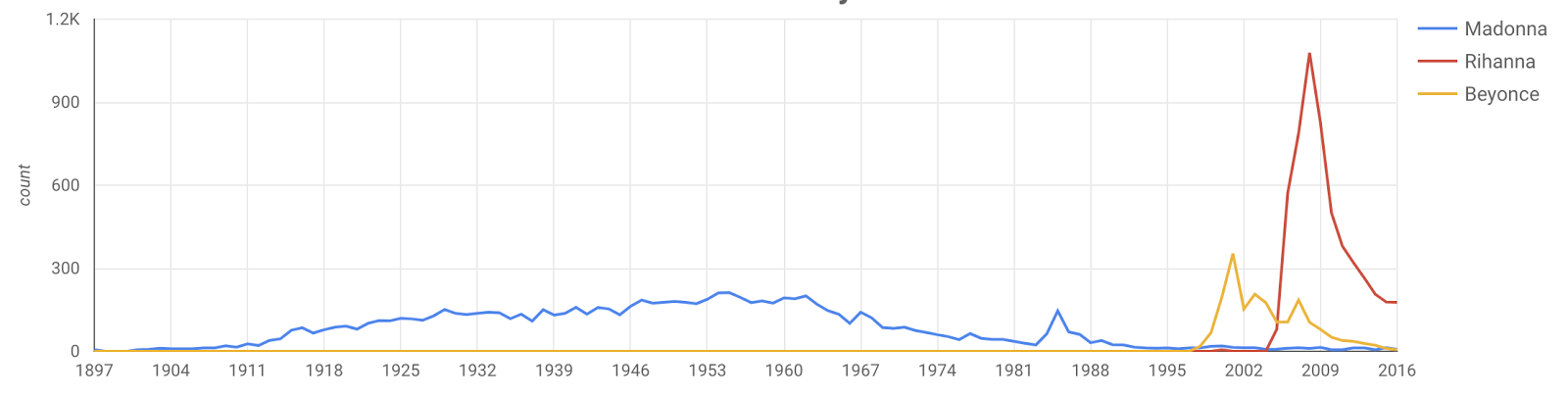
The Diva effect
When a pop star starts getting famous, people name their kids after them for the first few years. But at some point they become such a big deal that nobody uses that name anymore.
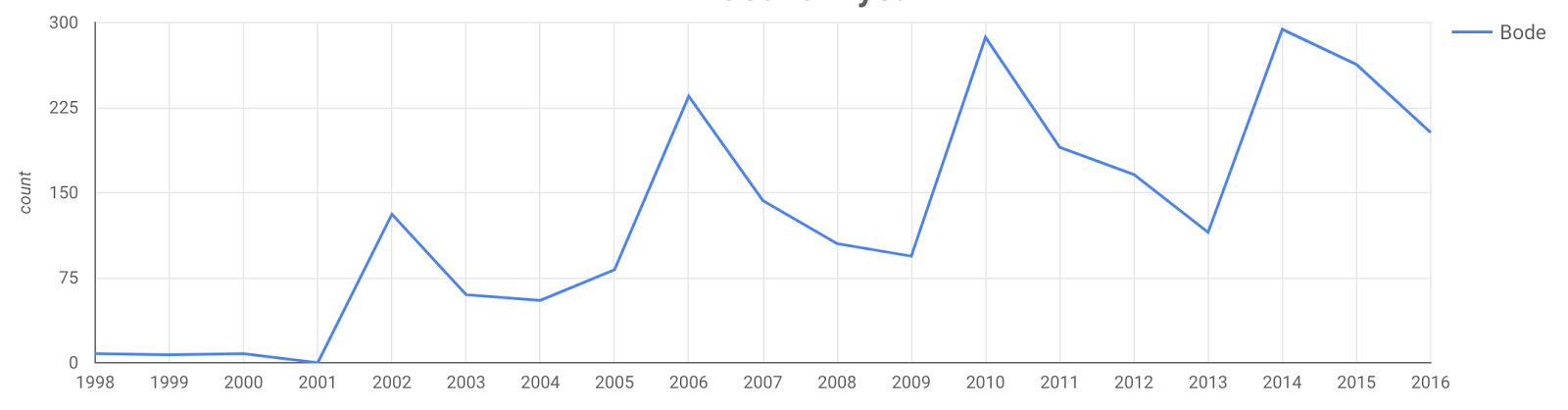
The Olympics effect
Most people have never heard of the name "Bode", but every four years during winter we get to see Bode Miller dazzle us all with his amazing skiing skills on TV, leading to a corresponding bump in names:
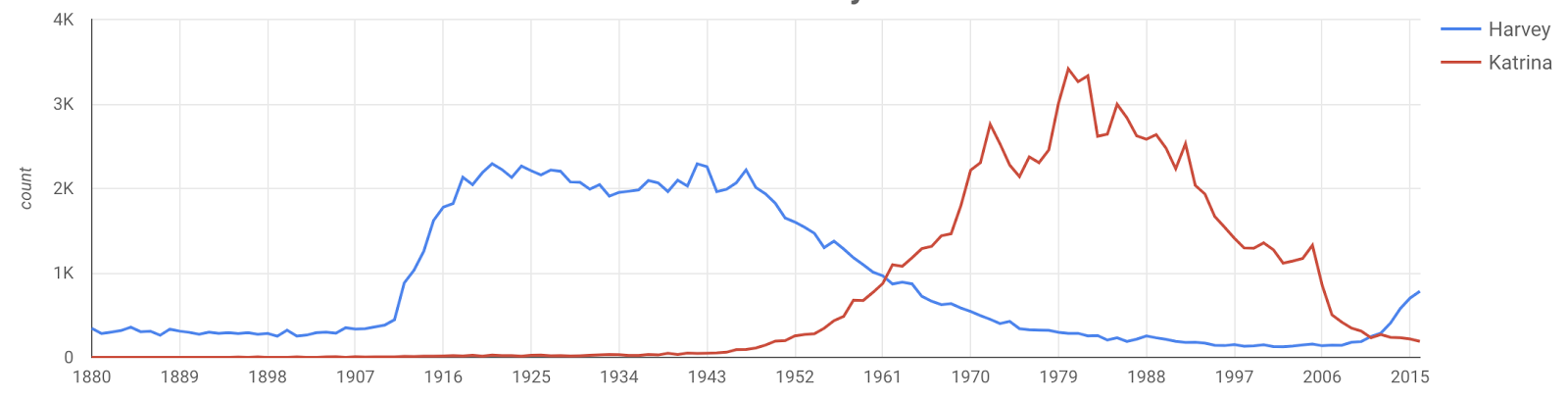
The Disaster effect
People stop naming their kids after anything associated with a disaster, be it natural or man-made. My prediction is the name "Harvey", which has had a recent resurgence, will significant decline after this year's hurricane.
Trendy names
There are many names that become extremely popular for a decade and then significantly decline. Some of these names come from movie characters or actors at the time.
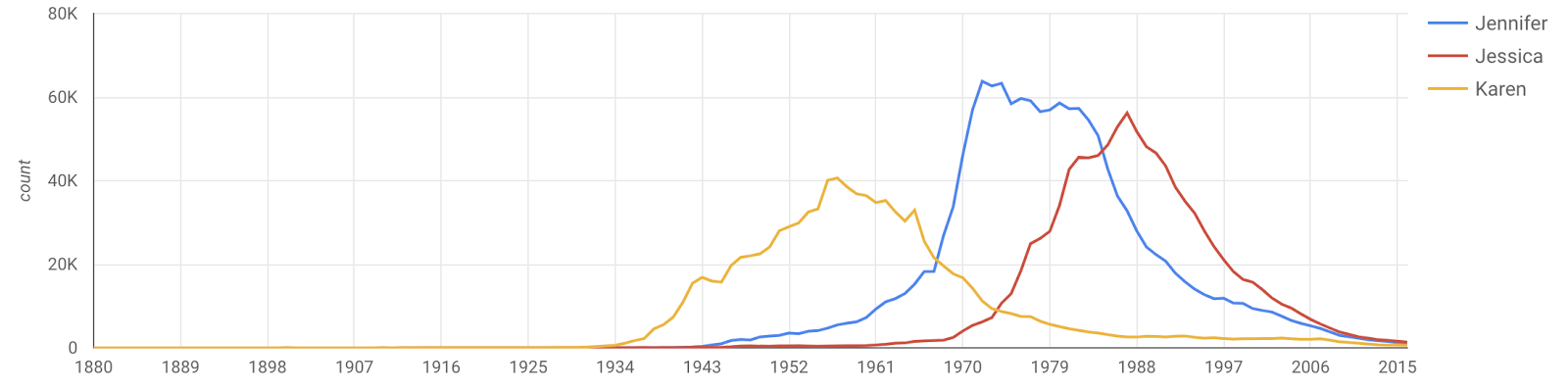
Here's the link to the visualization again. Let me know if you find anything interesting!
The Diva effect
When a pop star starts getting famous, people name their kids after them for the first few years. But at some point they become such a big deal that nobody uses that name anymore.
The Olympics effect
Most people have never heard of the name "Bode", but every four years during winter we get to see Bode Miller dazzle us all with his amazing skiing skills on TV, leading to a corresponding bump in names:
The Disaster effect
People stop naming their kids after anything associated with a disaster, be it natural or man-made. My prediction is the name "Harvey", which has had a recent resurgence, will significant decline after this year's hurricane.
Trendy names
There are many names that become extremely popular for a decade and then significantly decline. Some of these names come from movie characters or actors at the time.
Here's the link to the visualization again. Let me know if you find anything interesting!
07 May 2017
Link roundup #10
Another big backlog of links from the past few months. I need to get better at sending these in smaller digests.
- Reverse engineering the 76477 "Space Invaders" sound effect chip from die photos
- Getting Started with Headless Chrome
- Host Identity Protocol (HIP) Domain Name System (DNS) Extension
- Software Developers After 40, 50 and 60 Who Hate Being A Manager
- Coding for SSDs – Part 1
- What We Actually Know About Software Development, and Why We Believe It's True
- "Sun decided that almost all Java errors must be recoverable, which results in lazy error handling like the above."
- Questions for our first 1:1
- Fuchsia: a new operating system
- Golang pkg/errors
- Structure and Interpretation of Computer Programs (well formatted)
- Visualizing Garbage Collection Algorithms
- Intel's first Optane SSD: 375GB that you can also use as RAM
- Apache Beam provides an advanced unified programming model, allowing you to implement batch and streaming data processing jobs that can run on any execution engine.
- The Reasonable Effectiveness of the Multiplicative Weights Update Algorithm
- Index 1,600,000,000 Keys with Automata and Rust
- Decentralized micropayments
- Management Is Dead, Long Live Management
- Better Compression with Zstandard
- Comparison of Hosted Continuous Integration products
- Viola is a tool for the development and support of visual interactive media applications. (1992)
- How I ended up writing a new real-time kernel
- Golang: Logging, interfaces, and allocation
- Seeing Theory: A visual introduction to probability and statistics.
- Annotation is now a web standard
- 120,000 consistent writes per second with Calvin
- Jepsen: CockroachDB beta-20160829
- You're better off using Exceptions
- TensorFlowOnSpark brings TensorFlow programs onto Apache Spark clusters
- Writing more legible SQL
- Documenting Architecture Decisions
- Let the Design Decision Stand
- New ASLR-busting JavaScript is about to make drive-by exploits much nastier
- Urbit is a virtual city of general-purpose personal servers.
- In Defense of C++
- Rust: Procedural Macros
- Things I Wish I Knew When I Started Building Reactive Systems
- Beringei: A high-performance time series storage engine
- SQL WITH: Performance Impacts
- My history with Forth & stack machines
- Modern C++ Features - decltype and std::declval
- Java Without If
- Things Every Hacker Once Knew
- Amazon Web Services' secret weapon: Its custom-made hardware and network
- The Monad Fear
- Becoming More Functional
- The Idea of Lisp
03 April 2017
Discovering my inner curmudgeon: A Linux laptop review
Quick refresher: I'm a life-long Mac user, but I was disappointed by Apple's latest MacBook Pro release. I researched a set of alternative computers to consider. And, as a surprise even to myself, I decided to leave the Mac platform.
I chose the HP Spectre x360 13" laptop that was released after CES 2017, the new version with a 4K display. I bought the machine from BestBuy (not an affiliate link) because that was the only retailer selling this configuration. My goal was to run Ubuntu Linux instead of Windows.
Here are my impressions from using this computer over the past month, followed by some realizations about myself.
Ubuntu
Installing Ubuntu was easy. The machine came with Windows 10 preinstalled. I used Windows' built-in Disk Management app to shrink the main partition and free up space for Linux. I loaded the Ubuntu image on a USB drive, which conveniently fit in the machine's USB-A port (missing on new Macs). Then I followed Ubuntu's simple install instructions, which required some BIOS changes to enable booting from USB.
Screen
The 4K screen on the Spectre x360 is gorgeous. The latest Ubuntu handles High DPI screens well, which surprised me. With a combination of the built-in settings app and additional packages like gnome-tweak-tool, you can get UI controls rendering on the 4K display at 2x native size, so they look right. You can also boost the default font size to make it proportional. There are even settings to adjust icon sizes in the window titlebar and task manager. It's fiddly, but I got everything set up relatively quickly.
Trackpad
The trackpad hardware rattles a little, but it follows your fingers well and supports multi-touch input in Ubuntu by default. However, you immediately realize that something is wrong when you try to type and the mouse starts jumping around. The default Synaptics driver for Linux doesn't properly ignore palm presses on this machine. The solution is to switch to the new libinput system. By adjusting the xinput settings you can get it to work decently well.
But the gestures I'm used to, like two finger swipe to go back in Chrome, or four-finger swipe to switch workspaces, don't work by default in Ubuntu. You have to use a tool like libinput-gestures to enable them. Even then, the gestures are only recognized about 50% of the time, which is frustrating. The "clickpad" functionality is also problematic: When you press your thumb on the dual-purpose trackpad/button surface in order to click, the system will often think you meant to move the mouse or you're trying to multi-touch resize. Again: It's frustrating.
Keyboard
Physically the keyboard is good. The keys have a lot of travel and I can type fast. The left control key is in the far bottom left so it's usable (unlike Macs that put the function key there). The arrow keys work well. One peculiarity is the keyboard has an extra column of keys on the right side, which includes Delete, Home, Page Up, Page Down, and End. This caused my muscle memory for switching from arrow keys to home row keys to be off by one column. This also puts your hands off center while typing, which can make you feel like you're slightly reaching on your right side.
At first I thought that the extra column of keys (Home, Page Up, etc) was superfluous. But after struggling to use Sublime Text while writing some code, I realized that the text input controls on Linux and Windows rely on these keys. It makes sense that HP decided to include them. As a Mac user I'm used to Command-Right going to the end of line, where a Windows or Linux user would reach for the End key. Remapping every key to match the Mac setup is possible, but hard to make consistent across all programs. The right thing to do is to relearn how to do text input with these new keys. I spent some time trying to retrain my muscle memory, but it was frustrating, like that summer when I tried Dvorak.
Sound
The machine comes with four speakers: two fancy Bang & Olufsen speakers on top, and two normal ones on the bottom. The top speakers don't work on Linux and there's a kernel bug open to figure it out. The bottom speakers do work, but they're too quiet. The headphone jack worked correctly, and it would even mute the speakers automatically when you plugged in headphones. I believe this only happened because I had upgraded my kernel to the bleeding edge 4.10 version in my attempts to make other hardware functional. I figure the community will eventually resolve the kernel bug, so the top speaker issue is likely temporary. But this situation emphasizes why HP needs to ship their own custom distribution of Windows with a bunch of extra magical drivers.
Battery & power
Initially the battery life was terrible. The 4K screen burns a lot of power. I also noticed that the CPU fan would turn on frequently and blow warm air out the left side of the machine. It's hot enough that it's very uncomfortable if it's on your lap. I figured out that this was mostly the result of a lack of power management in Ubuntu's default configuration. You can enable a variety of powersaving tools, including powertop and pm-powersave. Intel also provides Linux firmware support to make the GPU idle properly. With all of these changes applied, my battery life got up to nearly 5 hours: a disappointment compared to the 9+ hours advertised. On a positive note, the USB-C charger works great and fills the battery quickly. It was also nice to be able to charge my Nexus X phone with the same plug.
Two-in-one
The Spectre x360 gets its name from the fact that its special hinges let the laptop's screen rotate completely around, turning it into a tablet. Without any special configuration, touching the screen in Ubuntu works properly for clicking, scrolling, and zooming. Touch even works for forward/back gestures that don't work on the trackpad. The keyboard and trackpad also automatically disable themselves when you rotate into tablet mode. You can set up Onboard, Gnome's on-screen keyboard, and it's decent. Screen auto-rotation doesn't work, but I was able to cobble something together using iio-sensor-proxy and this one-off script. Once I did this, though, I realized that the 16:9 aspect ratio of the screen is too much: It hurts my eyeballs to scan down so far vertically in tablet mode.
Window manager and programs
I haven't used Linux regularly on a desktop machine since RedHat 5.0 in 1998. It's come a long way. Ubuntu boots very quickly. The default UI uses their Unity window manager, a Gnome variant, and it's decent. I tried plain Gnome and it felt clunky in comparison. I ended up liking KDE the most, and would choose the KDE Kubuntu variant if I were to start again. Overall the KDE window manager felt nice and did everything I needed.
On this journey back into Linux I realized that most of the time I only use eight programs: a web browser (Chrome), a terminal (no preference), a text editor (Sublime Text 3), a settings configurator, a GUI file manager, an automatic backup process (Arq), a Flux-like screen dimmer, and an image editor (the Gimp). My requirements beyond that are also simple. I rely on four widgets: clock, wifi status, battery level, and volume level. I need a task manager (like the Dock) and virtual work spaces (like Mission Control / Expose). I don't use desktop icons, notifications, recent apps, search, or an applications menu. I was able to accommodate all of these preferences on Linux.
Conclusion
If you're in the market for a new laptop, by all means check this one out. However, I'll be selling my Spectre x360 and going back to my mid-2012 MacBook Air. It's not HP's fault or because of the Linux desktop. The problem is how I value my time.
I'm so accustomed to the UX of a Mac that it's extremely difficult for me to use anything else as efficiently. My brain is tuned to a Mac's trackpad, its keyboard layout, its behaviors of text editing, etc. Using the HP machine and Linux slows me down so much that it feels like I'm starting over. When I'm using my computer I want to spend my time improving my (programming, writing, etc) skills. I want to invest all of my "retraining" energy into understanding unfamiliar topics, like new functional languages and homomorphic encryption. I don't want to waste my time relearning the fundamentals.
In contrast, I've spent the past two years learning how to play the piano. It's required rote memorization and repeated physical exercises. By spending time practicing piano, I've opened myself up to ideas that I couldn't appreciate before. I've learned things about music that I couldn't comprehend in the past. My retraining efforts have expanded my horizons. I'm skeptical that adopting HP hardware and the Linux desktop could have a similar effect on me.
I'm stubborn. There will come a time when I need to master a new way of working to stay relevant, much like how telegraph operators had to switch from Morse code to teletypes. I hope that I will have the patience and foresight to make such a transition smoothly in the future. Choosing to retrain only when it would create new possibilities seems like a good litmus test for achieving that goal. In the meantime, I'll keep using a Mac.
I chose the HP Spectre x360 13" laptop that was released after CES 2017, the new version with a 4K display. I bought the machine from BestBuy (not an affiliate link) because that was the only retailer selling this configuration. My goal was to run Ubuntu Linux instead of Windows.
Here are my impressions from using this computer over the past month, followed by some realizations about myself.
Ubuntu
Installing Ubuntu was easy. The machine came with Windows 10 preinstalled. I used Windows' built-in Disk Management app to shrink the main partition and free up space for Linux. I loaded the Ubuntu image on a USB drive, which conveniently fit in the machine's USB-A port (missing on new Macs). Then I followed Ubuntu's simple install instructions, which required some BIOS changes to enable booting from USB.
Screen
The 4K screen on the Spectre x360 is gorgeous. The latest Ubuntu handles High DPI screens well, which surprised me. With a combination of the built-in settings app and additional packages like gnome-tweak-tool, you can get UI controls rendering on the 4K display at 2x native size, so they look right. You can also boost the default font size to make it proportional. There are even settings to adjust icon sizes in the window titlebar and task manager. It's fiddly, but I got everything set up relatively quickly.
Trackpad
The trackpad hardware rattles a little, but it follows your fingers well and supports multi-touch input in Ubuntu by default. However, you immediately realize that something is wrong when you try to type and the mouse starts jumping around. The default Synaptics driver for Linux doesn't properly ignore palm presses on this machine. The solution is to switch to the new libinput system. By adjusting the xinput settings you can get it to work decently well.
But the gestures I'm used to, like two finger swipe to go back in Chrome, or four-finger swipe to switch workspaces, don't work by default in Ubuntu. You have to use a tool like libinput-gestures to enable them. Even then, the gestures are only recognized about 50% of the time, which is frustrating. The "clickpad" functionality is also problematic: When you press your thumb on the dual-purpose trackpad/button surface in order to click, the system will often think you meant to move the mouse or you're trying to multi-touch resize. Again: It's frustrating.
Keyboard
Physically the keyboard is good. The keys have a lot of travel and I can type fast. The left control key is in the far bottom left so it's usable (unlike Macs that put the function key there). The arrow keys work well. One peculiarity is the keyboard has an extra column of keys on the right side, which includes Delete, Home, Page Up, Page Down, and End. This caused my muscle memory for switching from arrow keys to home row keys to be off by one column. This also puts your hands off center while typing, which can make you feel like you're slightly reaching on your right side.
At first I thought that the extra column of keys (Home, Page Up, etc) was superfluous. But after struggling to use Sublime Text while writing some code, I realized that the text input controls on Linux and Windows rely on these keys. It makes sense that HP decided to include them. As a Mac user I'm used to Command-Right going to the end of line, where a Windows or Linux user would reach for the End key. Remapping every key to match the Mac setup is possible, but hard to make consistent across all programs. The right thing to do is to relearn how to do text input with these new keys. I spent some time trying to retrain my muscle memory, but it was frustrating, like that summer when I tried Dvorak.
Sound
The machine comes with four speakers: two fancy Bang & Olufsen speakers on top, and two normal ones on the bottom. The top speakers don't work on Linux and there's a kernel bug open to figure it out. The bottom speakers do work, but they're too quiet. The headphone jack worked correctly, and it would even mute the speakers automatically when you plugged in headphones. I believe this only happened because I had upgraded my kernel to the bleeding edge 4.10 version in my attempts to make other hardware functional. I figure the community will eventually resolve the kernel bug, so the top speaker issue is likely temporary. But this situation emphasizes why HP needs to ship their own custom distribution of Windows with a bunch of extra magical drivers.
Battery & power
Initially the battery life was terrible. The 4K screen burns a lot of power. I also noticed that the CPU fan would turn on frequently and blow warm air out the left side of the machine. It's hot enough that it's very uncomfortable if it's on your lap. I figured out that this was mostly the result of a lack of power management in Ubuntu's default configuration. You can enable a variety of powersaving tools, including powertop and pm-powersave. Intel also provides Linux firmware support to make the GPU idle properly. With all of these changes applied, my battery life got up to nearly 5 hours: a disappointment compared to the 9+ hours advertised. On a positive note, the USB-C charger works great and fills the battery quickly. It was also nice to be able to charge my Nexus X phone with the same plug.
Two-in-one
The Spectre x360 gets its name from the fact that its special hinges let the laptop's screen rotate completely around, turning it into a tablet. Without any special configuration, touching the screen in Ubuntu works properly for clicking, scrolling, and zooming. Touch even works for forward/back gestures that don't work on the trackpad. The keyboard and trackpad also automatically disable themselves when you rotate into tablet mode. You can set up Onboard, Gnome's on-screen keyboard, and it's decent. Screen auto-rotation doesn't work, but I was able to cobble something together using iio-sensor-proxy and this one-off script. Once I did this, though, I realized that the 16:9 aspect ratio of the screen is too much: It hurts my eyeballs to scan down so far vertically in tablet mode.
Window manager and programs
I haven't used Linux regularly on a desktop machine since RedHat 5.0 in 1998. It's come a long way. Ubuntu boots very quickly. The default UI uses their Unity window manager, a Gnome variant, and it's decent. I tried plain Gnome and it felt clunky in comparison. I ended up liking KDE the most, and would choose the KDE Kubuntu variant if I were to start again. Overall the KDE window manager felt nice and did everything I needed.
On this journey back into Linux I realized that most of the time I only use eight programs: a web browser (Chrome), a terminal (no preference), a text editor (Sublime Text 3), a settings configurator, a GUI file manager, an automatic backup process (Arq), a Flux-like screen dimmer, and an image editor (the Gimp). My requirements beyond that are also simple. I rely on four widgets: clock, wifi status, battery level, and volume level. I need a task manager (like the Dock) and virtual work spaces (like Mission Control / Expose). I don't use desktop icons, notifications, recent apps, search, or an applications menu. I was able to accommodate all of these preferences on Linux.
Conclusion
If you're in the market for a new laptop, by all means check this one out. However, I'll be selling my Spectre x360 and going back to my mid-2012 MacBook Air. It's not HP's fault or because of the Linux desktop. The problem is how I value my time.
I'm so accustomed to the UX of a Mac that it's extremely difficult for me to use anything else as efficiently. My brain is tuned to a Mac's trackpad, its keyboard layout, its behaviors of text editing, etc. Using the HP machine and Linux slows me down so much that it feels like I'm starting over. When I'm using my computer I want to spend my time improving my (programming, writing, etc) skills. I want to invest all of my "retraining" energy into understanding unfamiliar topics, like new functional languages and homomorphic encryption. I don't want to waste my time relearning the fundamentals.
In contrast, I've spent the past two years learning how to play the piano. It's required rote memorization and repeated physical exercises. By spending time practicing piano, I've opened myself up to ideas that I couldn't appreciate before. I've learned things about music that I couldn't comprehend in the past. My retraining efforts have expanded my horizons. I'm skeptical that adopting HP hardware and the Linux desktop could have a similar effect on me.
I'm stubborn. There will come a time when I need to master a new way of working to stay relevant, much like how telegraph operators had to switch from Morse code to teletypes. I hope that I will have the patience and foresight to make such a transition smoothly in the future. Choosing to retrain only when it would create new possibilities seems like a good litmus test for achieving that goal. In the meantime, I'll keep using a Mac.
21 January 2017
Link roundup #9
Here's a big backlog of links I've enjoyed recently.
- A Trip Down The League of Legends Graphics Pipelines
- Introducing Riptide: WebKit’s Retreating Wavefront Concurrent Garbage Collector
- Rust vs. Go
- My Go Resolutions for 2017 (by Russ Cox)
- OK Log is a distributed and coördination-free log management system
- RethinkDB: why we failed
- Webmention: W3C Recommendation
- Add a const here, delete a const there…
- Goroutines, Nonblocking I/O, And Memory Usage
- On Getting Old(er) in Tech
- Server-Side Rendering isn't a silver bullet!
- Why does calloc exist?
- How the Circle Line rogue train was caught with data
- Disadvantages of purely functional programming
- Grumpy: Go running Python!
- A Typed pluck: exploring TypeScript 2.1’s mapped types
10 December 2016
The Paradox of UX
A realization I had this week:
Why?
Paid software is worth buying because it solves an immediate need for the user. Developers of paid software are incentivized to put all of their energy into building more features to solve more problems that are worth paying for. There's no reason to improve usability as long as customers are satisfied enough to keep paying. Each time you make the software a little more complicated, you make it more valuable, leading to more revenue. It's self-reinforcing.
With free/unpaid software, the goal is to get the largest audience you can. The developers' revenue comes from indirect sources like advertising. The bigger their audience, the more money they earn. They maximize their audience by improving usability, broadening appeal, and streamlining. Each time the software gets a little easier to use, more people can start using it, leading to a larger audience, which generates more revenue. It's similarly self-reinforcing.
The conclusions I draw from this:
1. Competition drives usability. Free apps must have great UX because they need to compete against other free apps for your attention and usage. Paid apps that don't have competition can ignore usability because there's no alternative for users.
2. If the market of customers is big enough, competing paid software will emerge. Once it does, it's just a matter of time before all software in the space reaches feature parity. (e.g., Photoshop vs. Pixelmator, Hipchat vs. Slack, AutoCAD vs. SolidWorks, GitHub vs. Bitbucket).
3. If your paid software has capable competitors, you must differentiate with the quality of your user experience. You're fooling yourself if you think that you'll be able to stay ahead by adding incremental features over time.
- Software that costs money often has terrible UX, despite the developers having the revenue and resources to improve it.
- In contrast, free/unpaid software often has great UX, even though users are unwilling to pay for it.
Why?
Paid software is worth buying because it solves an immediate need for the user. Developers of paid software are incentivized to put all of their energy into building more features to solve more problems that are worth paying for. There's no reason to improve usability as long as customers are satisfied enough to keep paying. Each time you make the software a little more complicated, you make it more valuable, leading to more revenue. It's self-reinforcing.
With free/unpaid software, the goal is to get the largest audience you can. The developers' revenue comes from indirect sources like advertising. The bigger their audience, the more money they earn. They maximize their audience by improving usability, broadening appeal, and streamlining. Each time the software gets a little easier to use, more people can start using it, leading to a larger audience, which generates more revenue. It's similarly self-reinforcing.
The conclusions I draw from this:
1. Competition drives usability. Free apps must have great UX because they need to compete against other free apps for your attention and usage. Paid apps that don't have competition can ignore usability because there's no alternative for users.
2. If the market of customers is big enough, competing paid software will emerge. Once it does, it's just a matter of time before all software in the space reaches feature parity. (e.g., Photoshop vs. Pixelmator, Hipchat vs. Slack, AutoCAD vs. SolidWorks, GitHub vs. Bitbucket).
3. If your paid software has capable competitors, you must differentiate with the quality of your user experience. You're fooling yourself if you think that you'll be able to stay ahead by adding incremental features over time.
01 December 2016
The JavaScript language continues to get bigger and more complex. Latest example. Please stop adding features to it!
26 November 2016
Link roundup #8
Quite a backlog of good links this time!
- Practical advice for analysis of large, complex data sets
- Go in [Jupyter] Notebooks
- History of Actors
- Proposal: Eliminate STW stack re-scanning [Golang]
- Static typing will not save us from broken software
- Measurement of Impulsive Thrust from a Closed Radio-Frequency Cavity in Vacuum
- New Support for Alternative Quantum View [pilot-wave theory]
- Coverage Error in Internet Surveys
- Work at different management levels
- Reflections of an "Old" Programmer
- Deep learning, model checking, AI, the no-homunculus principle, and the unitary nature of consciousness
12 November 2016
Building robust software with rigorous design documents
My work is centered around building software. In the past, I've been the primary designer and implementor of large software systems, collaborating with many engineers to launch programs into production. Lately, I've been spending much more of my time guiding others in their software design efforts.
Why design software at all? Why not just start writing code and see where it leads? For many problems, skipping design totally works and is the fastest path. In these cases, you can usually refactor your way into a reasonable implementation. I think you only need to design in advance once the scope of the software system you're building is large enough that it won't all fit in your head, or complex enough that it's difficult to explain in a short conversion.
Writing a design document is how software engineers use simple language to capture their investigations into a problem. Once someone has written a design document, a technical lead — often the same person who was the author of the document — can use it to set target milestones and drive an implementation project to completion.
I realized that I've never actually written down what I look for in a design document. So my goal in this post is to give you a sense of what I think it takes to write a design document, what the spectrum of design documentation looks like in my experience, and what I consider to be the crucial elements of good design.
How to get started
First, before writing any kind of formal documentation, you need to prototype. You need to gain experience working in the problem domain before you can establish any legitimate opinions.
The goal of making a prototype is to investigate the unknown. Before you start prototyping, you may have some sense of the "known unknowns", but understand little about them in practice. By prototyping, you'll improve your intuition so you can better anticipate future problems. You may even get lucky and discover some unknown unknowns that you couldn't have imagined.
Concretely, prototyping is getting the system to work end-to-end in one dimension (e.g., a tracer bullet implementation). It's working out and proving that the most confusing or risky part of the system is possible (e.g., the core algorithm). Or prototyping is dry-fitting all of the moving parts together, but without handling any of the complex edge cases. How you go about prototyping reflects the kind of problem you're trying to solve.
How to write a design document
The first draft of your "design document" is the code for your first working prototype. The second draft is a rough document that explains everything you learned from building that prototype. The third draft includes a proposal for a better design that addresses all of the difficulties you discovered while prototyping. You should share the third draft with the rest of your team to get their feedback. Then the final draft is a revision of the document that addresses all of the questions and concerns raised by your peers.
Design documents should be as short as possible. They should include enough detail to explain what you need to know and nothing more. Your design doc shouldn't include any code unless that code is critical for the reader to understand how the whole design fits together (e.g., an especially difficult algorithm that relies on a specific programming language's constructs).
There are five major sections that I recommend you have in a design document, and in this order:
1. Background
This is information that puts the design in context. You should assume that your reader knows very little about the subject matter. Here you should include everything they'll need to know about the problem domain to understand your design. Links to other design documents, product requirements, and existing code references are extremely useful.
When writing the background section, you should assume that it will be read by someone with no context. A couple of years from now, all of the knowledge that led to your implementation will likely be forgotten. You should treat the background section like it's a letter to the future about what you understood at this time in the past.
2. Goals and non-goals
These are the motivations for your project. Here you summarize the intentions of your proposed implementation. This section should explain the measurable impact of your design. You should provide estimates of how much you're going to help or hurt each quantifiable metric that you care about.
This section should also explicitly list the outcomes that you're not trying to achieve. This includes metrics you won't track, features you won't support, future functionality that isn't being considered yet, etc. Tracking non-goals is the primary way you can prevent scope creep. As your peers review your design document and bring up questions and comments, the non-goals section should grow accordingly to rule out entire areas of irrelevant investigation.
3. Overview
This section is a coarse explanation of what the software system is going to do. Engineers familiar with the problem and context should be able to read the overview and get a general sense of what the major moving parts of the design are. By reading the overview section, a fellow engineer should be able to formulate a set of important questions about the design. The purpose of the rest of the design document is to answer those questions in advance.
4. Detail
This section goes through each major component from the design overview and explains it in precise language. You should answer every reasonable question you can think of from the design overview. This is where you put things like sequence diagrams. You may also list step-by-step recipes that you'll employ in the software to solve the primary problem and various subproblems.
5. Risks
After reading the detailed design, your readers should have a sense of where your design may go wrong. It's a given that your system will fail to work in certain ways. You're making time vs. space trade-offs that are incorrect. Tolerances for the resources you need, or the wiggle room you'll have to accommodate changes will be insufficient. Edge-cases you ignored will turn out to be the most important functionality. In this section you should list how you anticipate your system will break, how likely you think those failures will be, and what you'll do to mitigate those problems before or when they occur.
What is the scope of a design document
After going through the distinct sections of a design document, there are still many open questions: How much detail should a design document include? How big of a scope should you address in a single design document? What should you expect a software engineer to produce on their own?
I'll answer these questions by trying to characterize the nature of problems that are solved by software engineers. You can identify distinct levels of software complexity by considering the size and shape of what's being confronted. Here's a conceptual diagram of what I consider to be the hierarchy of scope that software engineers handle:
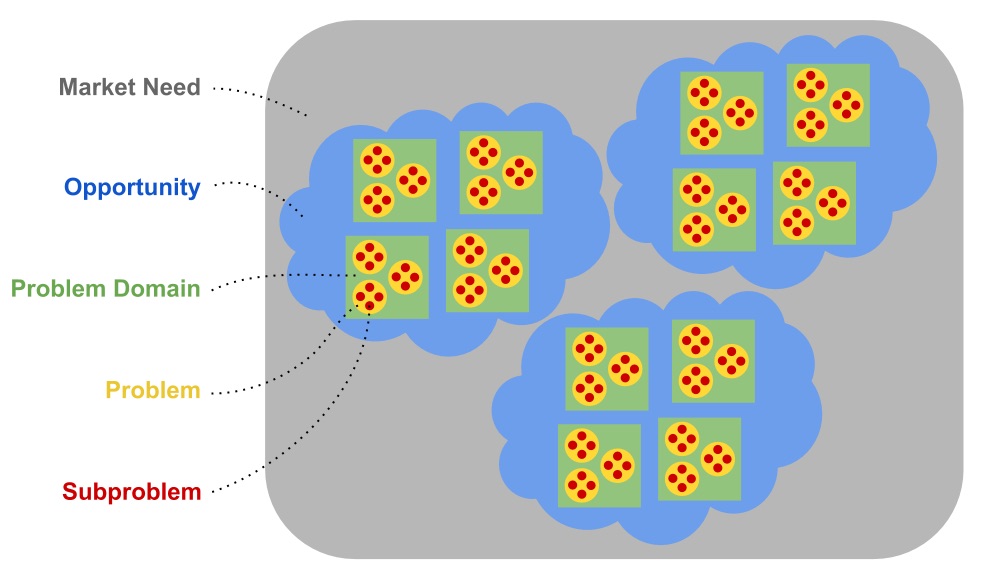
The breakdown of this hierarchy is:
Here's a concrete example of what I mean with this hierarchy:
Some problems contain dozens of subproblems. Some problem domains contain hundreds of problems. Some opportunities contain vast numbers of related problem domains. And so on. This hierarchy diagram isn't meant to quantify the size ratios between these concepts. I'm trying to express their unique nature and the relationships between them.
The detail I expect to see in a design document, and thus the document's length, varies based on the scope of the project. Here's roughly the breakdown of design document length that I've seen in my career:
What's surprising about this table is that designs addressing a problem domain are the most rigorous. The design detail required to handle a problem domain far exceeds that of any other scope. Design detail doesn't continue to increase as scope grows. Instead, as an engineer's scope expands to include multiple problem domains, multiple opportunities, and entire market needs, the level of detail I've seen in design documents plummets.
I think the reason these documents are so rigorous is that understanding a problem domain is the most difficult task an engineer can handle on their own. These design documents aren't immense because they're overly verbose, they're extremely detailed because that's what it takes to become an expert in a problem domain.
But there aren't enough hours in the day to become an expert in multiple areas. Once someone's scope gets large enough, they must start handing off problem domains to other engineers who can devote all of their time to each area. It's unrealistic for one person to write design documents for many problem domains. Thus, the design documents for larger scopes actually get smaller.
How to design for a whole problem domain
So what, exactly, goes into a design document for a problem domain? What makes these docs so detailed and rigorous? I believe that the hallmark of these designs is an extremely thorough assessment of risk.
As the owner of a problem domain, you need to look into the future and anticipate everything that could go wrong. Your goal is to identify all of the possible problems that will need to be addressed by your design and implementation. You investigate each of these problems deeply enough to provide a useful explanation of what they mean in your design document. Then you rank these problems as risks based on a combination of severity (low, medium, high) and likelihood (doubtful, potential, definite).
For each risk, you must decide:
You should not plan to mitigate every risk in advance; this is impossible because the scope of the problem domain you've taken on is too large and the unknowns are too complex. Instead, your design document should identify the most likely scenarios and outline potential mitigations for them. These mitigations can end up being large projects in themselves, and often need to be designed and implemented by dedicated teams of engineers.
To be more concrete about what a problem domain design document looks like, let's assume that you've taken on the cloud computing example from before. The problem domain you're addressing is "virtual machines". Here's what you'd cover in your risk assessment.
First, you'd enumerate the major concerns within this problem domain:
Then you'd identify expected subproblems:
For each problem and subproblem you'd flesh out the potential solutions in the design document. You may write small programs to verify assumptions, do load tests to find the realistic limits of infrastructure, forecast reasonable estimates for capacity, etc. What you hope to learn during the design phase is if there are any major dealbreakers that could undermine the viability of your design.
For example, when digging into the I/O performance problem, you may find through experimentation that all VM guest operating systems will need to do a number of disk reads while idling. You may then measure how many reads each VM will need on average, and use that result to estimate the maximum number of VMs per physical machine and local disk. You may discover that local disk performance will severely limit your system's overall scalability. At this point you should document the reasoning that led you to this conclusion and show your work.
Once you've identified the potential dealbreaker, you should figure out if it's viable to launch your virtual machine product without first solving the local disk issue. Your proposed design should list what you'd do if demand grew too quickly, such as requiring a wait-list for new users, limiting each user to a maximum quota of allowed VMs, throwing money at the problem with more physical hardware, etc. Your document should explain the whole range of alternatives and settle on which ones are the most prudent to implement for launch.
By recognizing such a large problem in advance, you may also reach the conclusion that you need to build a virtual local disk system in order to release your product at all. That may severely delay your timeline because the problems you need to address for launch have become much larger than you originally anticipated. Or maybe you decide to launch anyways.
The point is that it's always much better to consider all the risks before you launch. It's acceptable to take risks as long as you're well informed. It's a disaster to learn about large risks once you're already on the path to failure.
Conclusion
Even though it's full of information, what's most impressive about a problem domain design document is that it doesn't feel like overdesign. The risk mitigations it includes are not overspecified. There's just enough detail to get a handle on the problem domain. When the engineering team begins implementing such a design, there's still a lot of flexibility to change how the problems are solved and how the implementation actually works.
In general, you're kidding yourself if you think that software will be built the way it was originally designed. The goal of these design documents isn't to provide the blueprints for software systems. The goal is to prepare your team for a journey into the unknown. The definitive yet incomplete nature of a problem domain design document is what makes it the pinnacle of good software design.
Why design software at all? Why not just start writing code and see where it leads? For many problems, skipping design totally works and is the fastest path. In these cases, you can usually refactor your way into a reasonable implementation. I think you only need to design in advance once the scope of the software system you're building is large enough that it won't all fit in your head, or complex enough that it's difficult to explain in a short conversion.
Writing a design document is how software engineers use simple language to capture their investigations into a problem. Once someone has written a design document, a technical lead — often the same person who was the author of the document — can use it to set target milestones and drive an implementation project to completion.
I realized that I've never actually written down what I look for in a design document. So my goal in this post is to give you a sense of what I think it takes to write a design document, what the spectrum of design documentation looks like in my experience, and what I consider to be the crucial elements of good design.
How to get started
First, before writing any kind of formal documentation, you need to prototype. You need to gain experience working in the problem domain before you can establish any legitimate opinions.
The goal of making a prototype is to investigate the unknown. Before you start prototyping, you may have some sense of the "known unknowns", but understand little about them in practice. By prototyping, you'll improve your intuition so you can better anticipate future problems. You may even get lucky and discover some unknown unknowns that you couldn't have imagined.
Concretely, prototyping is getting the system to work end-to-end in one dimension (e.g., a tracer bullet implementation). It's working out and proving that the most confusing or risky part of the system is possible (e.g., the core algorithm). Or prototyping is dry-fitting all of the moving parts together, but without handling any of the complex edge cases. How you go about prototyping reflects the kind of problem you're trying to solve.
How to write a design document
The first draft of your "design document" is the code for your first working prototype. The second draft is a rough document that explains everything you learned from building that prototype. The third draft includes a proposal for a better design that addresses all of the difficulties you discovered while prototyping. You should share the third draft with the rest of your team to get their feedback. Then the final draft is a revision of the document that addresses all of the questions and concerns raised by your peers.
Design documents should be as short as possible. They should include enough detail to explain what you need to know and nothing more. Your design doc shouldn't include any code unless that code is critical for the reader to understand how the whole design fits together (e.g., an especially difficult algorithm that relies on a specific programming language's constructs).
There are five major sections that I recommend you have in a design document, and in this order:
1. Background
This is information that puts the design in context. You should assume that your reader knows very little about the subject matter. Here you should include everything they'll need to know about the problem domain to understand your design. Links to other design documents, product requirements, and existing code references are extremely useful.
When writing the background section, you should assume that it will be read by someone with no context. A couple of years from now, all of the knowledge that led to your implementation will likely be forgotten. You should treat the background section like it's a letter to the future about what you understood at this time in the past.
2. Goals and non-goals
These are the motivations for your project. Here you summarize the intentions of your proposed implementation. This section should explain the measurable impact of your design. You should provide estimates of how much you're going to help or hurt each quantifiable metric that you care about.
This section should also explicitly list the outcomes that you're not trying to achieve. This includes metrics you won't track, features you won't support, future functionality that isn't being considered yet, etc. Tracking non-goals is the primary way you can prevent scope creep. As your peers review your design document and bring up questions and comments, the non-goals section should grow accordingly to rule out entire areas of irrelevant investigation.
3. Overview
This section is a coarse explanation of what the software system is going to do. Engineers familiar with the problem and context should be able to read the overview and get a general sense of what the major moving parts of the design are. By reading the overview section, a fellow engineer should be able to formulate a set of important questions about the design. The purpose of the rest of the design document is to answer those questions in advance.
4. Detail
This section goes through each major component from the design overview and explains it in precise language. You should answer every reasonable question you can think of from the design overview. This is where you put things like sequence diagrams. You may also list step-by-step recipes that you'll employ in the software to solve the primary problem and various subproblems.
5. Risks
After reading the detailed design, your readers should have a sense of where your design may go wrong. It's a given that your system will fail to work in certain ways. You're making time vs. space trade-offs that are incorrect. Tolerances for the resources you need, or the wiggle room you'll have to accommodate changes will be insufficient. Edge-cases you ignored will turn out to be the most important functionality. In this section you should list how you anticipate your system will break, how likely you think those failures will be, and what you'll do to mitigate those problems before or when they occur.
What is the scope of a design document
After going through the distinct sections of a design document, there are still many open questions: How much detail should a design document include? How big of a scope should you address in a single design document? What should you expect a software engineer to produce on their own?
I'll answer these questions by trying to characterize the nature of problems that are solved by software engineers. You can identify distinct levels of software complexity by considering the size and shape of what's being confronted. Here's a conceptual diagram of what I consider to be the hierarchy of scope that software engineers handle:
The breakdown of this hierarchy is:
- Market need: Broad category of goods and services that people and organizations desire.
- Opportunity: Related ways of addressing those market needs.
- Problem domain: Vast areas of complexity that must be understood and addressed to seize such opportunities.
- Problem: Distinct issues in the problem domain that must be solved in order to advance towards the opportunity.
- Subproblem: The many aspects of a larger issue that must be handled in order to solve the whole problem.
Here's a concrete example of what I mean with this hierarchy:
- Market need: Hosting websites
- Opportunity: Cloud computing
- Problem domain: Virtual machines
- Problem: CPU performance
- Subproblems: context switching; cache invalidation
Some problems contain dozens of subproblems. Some problem domains contain hundreds of problems. Some opportunities contain vast numbers of related problem domains. And so on. This hierarchy diagram isn't meant to quantify the size ratios between these concepts. I'm trying to express their unique nature and the relationships between them.
The detail I expect to see in a design document, and thus the document's length, varies based on the scope of the project. Here's roughly the breakdown of design document length that I've seen in my career:
| Scope | Design document length |
|---|---|
| Subproblem | 500 words |
| Problem | 2,000 words |
| Problem domain | 8,000 words |
| Opportunity | 1,500 words |
| Market need | 1,000 words |
What's surprising about this table is that designs addressing a problem domain are the most rigorous. The design detail required to handle a problem domain far exceeds that of any other scope. Design detail doesn't continue to increase as scope grows. Instead, as an engineer's scope expands to include multiple problem domains, multiple opportunities, and entire market needs, the level of detail I've seen in design documents plummets.
I think the reason these documents are so rigorous is that understanding a problem domain is the most difficult task an engineer can handle on their own. These design documents aren't immense because they're overly verbose, they're extremely detailed because that's what it takes to become an expert in a problem domain.
But there aren't enough hours in the day to become an expert in multiple areas. Once someone's scope gets large enough, they must start handing off problem domains to other engineers who can devote all of their time to each area. It's unrealistic for one person to write design documents for many problem domains. Thus, the design documents for larger scopes actually get smaller.
How to design for a whole problem domain
So what, exactly, goes into a design document for a problem domain? What makes these docs so detailed and rigorous? I believe that the hallmark of these designs is an extremely thorough assessment of risk.
As the owner of a problem domain, you need to look into the future and anticipate everything that could go wrong. Your goal is to identify all of the possible problems that will need to be addressed by your design and implementation. You investigate each of these problems deeply enough to provide a useful explanation of what they mean in your design document. Then you rank these problems as risks based on a combination of severity (low, medium, high) and likelihood (doubtful, potential, definite).
For each risk, you must decide:
- Does it need to be mitigated in order to ship the minimum viable product?
- Can it be addressed after shipping without hindering the product initially?
- How will it be addressed if certain behaviors become worse over time?
You should not plan to mitigate every risk in advance; this is impossible because the scope of the problem domain you've taken on is too large and the unknowns are too complex. Instead, your design document should identify the most likely scenarios and outline potential mitigations for them. These mitigations can end up being large projects in themselves, and often need to be designed and implemented by dedicated teams of engineers.
To be more concrete about what a problem domain design document looks like, let's assume that you've taken on the cloud computing example from before. The problem domain you're addressing is "virtual machines". Here's what you'd cover in your risk assessment.
First, you'd enumerate the major concerns within this problem domain:
- CPU performance
- Security
- Memory performance
- I/O performance
- and so on ...
Then you'd identify expected subproblems:
- CPU Performance
- Instruction cache thrashing due to context switching
- Branch prediction failures
- Kernel lock contention
- Security
- CPU instructions that can exploit ring 0
- Multi-threading exploits to system calls
- Shared address space between guest and host OS
- DMA vulnerabilities
- Memory performance
- Data cache performance because of lack of CPU pinning and NUMA architectures
- Page alignment conflicts between virtual machine address space and host OS address space
- Endianness discrepancies
- Oversubscribing memory to increase multi-tenancy
- Memory compression and duplicate page merging
- I/O performance
- System call context switching overhead
- Avoiding copies for network sends
- Local disk access fairness
- Latency vs. throughput interplay when the VM workloads on a single host machine are wildly different
- and so on...
For each problem and subproblem you'd flesh out the potential solutions in the design document. You may write small programs to verify assumptions, do load tests to find the realistic limits of infrastructure, forecast reasonable estimates for capacity, etc. What you hope to learn during the design phase is if there are any major dealbreakers that could undermine the viability of your design.
For example, when digging into the I/O performance problem, you may find through experimentation that all VM guest operating systems will need to do a number of disk reads while idling. You may then measure how many reads each VM will need on average, and use that result to estimate the maximum number of VMs per physical machine and local disk. You may discover that local disk performance will severely limit your system's overall scalability. At this point you should document the reasoning that led you to this conclusion and show your work.
Once you've identified the potential dealbreaker, you should figure out if it's viable to launch your virtual machine product without first solving the local disk issue. Your proposed design should list what you'd do if demand grew too quickly, such as requiring a wait-list for new users, limiting each user to a maximum quota of allowed VMs, throwing money at the problem with more physical hardware, etc. Your document should explain the whole range of alternatives and settle on which ones are the most prudent to implement for launch.
By recognizing such a large problem in advance, you may also reach the conclusion that you need to build a virtual local disk system in order to release your product at all. That may severely delay your timeline because the problems you need to address for launch have become much larger than you originally anticipated. Or maybe you decide to launch anyways.
The point is that it's always much better to consider all the risks before you launch. It's acceptable to take risks as long as you're well informed. It's a disaster to learn about large risks once you're already on the path to failure.
Conclusion
Even though it's full of information, what's most impressive about a problem domain design document is that it doesn't feel like overdesign. The risk mitigations it includes are not overspecified. There's just enough detail to get a handle on the problem domain. When the engineering team begins implementing such a design, there's still a lot of flexibility to change how the problems are solved and how the implementation actually works.
In general, you're kidding yourself if you think that software will be built the way it was originally designed. The goal of these design documents isn't to provide the blueprints for software systems. The goal is to prepare your team for a journey into the unknown. The definitive yet incomplete nature of a problem domain design document is what makes it the pinnacle of good software design.
30 October 2016
Realistic alternatives to Apple computers
I'm disappointed with the new MacBook Pros and I wrote my thoughts about them here. Since the announcement, I've been researching all of my options and weighing the pros and cons. What follows comes from my own assessment of 16 laptops, their features, and reviews I've read about them. I'll highlight the ones which I think are the top five alternatives to Apple's computers. At the end there is a grid of all the options and links to more info. The machines I'm evaluating are either for sale right now or will be shipping by the end of the year. I'm not holding out for any rumored products.
These are the attributes that I think are important when choosing a new laptop:
Must have:
Prefer:
Ambivalent:
Avoid:
It's worth emphasizing how valuable Thunderbolt 3 is. With its 40Gbps transfer rate, "external GPU" enclosures have become a real thing and the options are increasing. In 2017, you should expect to dock your laptop into a gnarly GPU and use it for some intensive computation (VR, 3D design, neural network back propagation). Thunderbolt 3 also makes it easy to connect into one or more 4K+ external displays when you're not on the go. Not having Thunderbolt 3 significantly limits your future options.
The other details to look for are Skylake (6th generation) vs. Kaby Lake (7th generation) processors, and Core i5/i7 vs. Core M processors. The differences are subtle but meaningful. All of the new MacBook Pros and the MacBook 12" have 6th generation CPUs. The MacBook Pros have i5/i7 chips. The 12" MacBooks have m3/m5/m7 chips. It's a bit odd that the latest and greatest from Apple includes chips that were released over a year ago.
Here's my list of options, ordered by which ones I'm most seriously considering:
1. HP Spectre x360
Official product page and someone else's review that I found helpful.
It doesn't have a HiDPI display, but everything else looks sleek and great. The previous year's model was also available in a 4K version, but that doesn't have any Thunderbolt 3 ports. If they do release a variation of the new one in 4K, that model would be the winner for me by every measure.

2. Razer Blade Stealth 4K
Official product page and someone else's review that I found helpful.
With extra ports and a thick bezel it's not as svelte as I'd like. But the build quality seems high and I bet the 4K display looks awesome. Razer's Core external GPU is the easiest setup of its kind right now. There's also a cheaper option for $1,249 with less storage and a 2560 x 1440 screen (which is HiDPI like a MacBook but not close to 4K).

3. Dell XPS 13
Official product page and someone else's review that I found helpful.
This laptop has a modern edge-to-edge screen, but it's not quite 4K.I wouldn't look forward to lugging around the Dell-specific power cable (and being screwed when I lose it). Update: Blaine Cook corrected me in the comments: It turns out that it can charge via USB-C in addition to the proprietary power plug. Hooray! — Its ports, slots, and camera are a bit quirky. But, strongly in favor, it's also the laptop that Linus uses! There's a cheaper version with less storage and a slower i5 CPU for $1,399.

4. HP EliteBook Folio G1
Official product page and someone else's review that I found helpful.
This machine is tiny, fanless, and looks like a MacBook Air at first glance. It has Thunderbolt 3 and none of the old ports weighting it down. And 4K! The biggest drawback is that the CPU is a 6th generation Core M processor instead of an i5 or i7. If the 12" MacBook is more your speed than the MacBook Pro, then this could be the right machine for you.

5. Lenovo Yoga 910
Official product page and someone else's review that I found helpful.
If this had a Thunderbolt 3 port, I think it would be the laptop to get. It has a 4K screen and the styling looks great. Unfortunately, instead of Thunderbolt 3, Lenovo included a USB-C port that only speaks USB 2.0 protocol (not a typo, it's version two) and is used for charging. There's a cheaper option with less storage and RAM for $1,429.

Conclusion
I'm still not sure which computer I'm going to get. I'm now looking through Linux distributions like Ubuntu and elementary OS to see what compatibility and usability are like. I doubt that 2017 will be the "year of the Linux laptop", but for the first time I'm willing to give it an honest try.
Make no mistake: I think that Apple computers are still gorgeous and a great choice for people who have the budget. I plan to continue recommending MacBooks to family members, friends, acquaintances, and all of the other non-technical people in my life. I think "it just works" is still true for the low-end, and that's ideal for consumers. But consumers have very different needs than professionals.
For a long time, Apple has been a lofty brand, the "insanely great" hardware that people bought because they aspired to "think different". It's looking like that era may be over. Apple may have completed their transition into a mass-market company that makes relatively high quality hardware for normal people. There's nothing wrong with that. But it's probably not for me.
Here's the full list of the computers I considered, in the order I ranked them:
These are the attributes that I think are important when choosing a new laptop:
Must have:
- 13" form-factor
- Thunderbolt 3 ports
- Headphone jack
- Works decently with Linux
Prefer:
- HiDPI display (more than 200 pixels per inch)
- 7th generation Core i7 CPU
- 16 GB of RAM
- USB-C ports
Ambivalent:
- Flip form-factor (aka "2-in-1")
- USB 3.0 old-style A connectors
- More than 6 hours of battery life
Avoid:
- Proprietary power plug (USB-C charging is better)
- HDMI ports
- SD card reader
- Display port
It's worth emphasizing how valuable Thunderbolt 3 is. With its 40Gbps transfer rate, "external GPU" enclosures have become a real thing and the options are increasing. In 2017, you should expect to dock your laptop into a gnarly GPU and use it for some intensive computation (VR, 3D design, neural network back propagation). Thunderbolt 3 also makes it easy to connect into one or more 4K+ external displays when you're not on the go. Not having Thunderbolt 3 significantly limits your future options.
The other details to look for are Skylake (6th generation) vs. Kaby Lake (7th generation) processors, and Core i5/i7 vs. Core M processors. The differences are subtle but meaningful. All of the new MacBook Pros and the MacBook 12" have 6th generation CPUs. The MacBook Pros have i5/i7 chips. The 12" MacBooks have m3/m5/m7 chips. It's a bit odd that the latest and greatest from Apple includes chips that were released over a year ago.
Here's my list of options, ordered by which ones I'm most seriously considering:
1. HP Spectre x360
Official product page and someone else's review that I found helpful.
It doesn't have a HiDPI display, but everything else looks sleek and great. The previous year's model was also available in a 4K version, but that doesn't have any Thunderbolt 3 ports. If they do release a variation of the new one in 4K, that model would be the winner for me by every measure.
| Price | $1,299 |
| Pros | Two Thunderbolt 3 ports. Charge via USB-C. 2-in-1 laptop. |
| Cons | HD Display. |
| Thickness | 13.71mm |
| Weight | 2.86lbs |
| Battery | 57Wh |
| Display | 1920 x 1080 (Touch) |
| CPU | Intel 7th Generation Core i7-7500U dual core |
| RAM | 16GB |
| Storage | 512GB Flash |
| Graphics | Intel HD Graphics 620 |
| Power plug | USB-C |
| Thunderbolt 3 ports | 2 |
| USB-C (non-Thunderbolt) ports | 0 |
| USB 3.0 A ports | 1 |
| SD slots | None |
| Video ports | None |
| Audio ports | Headphone/mic jack |
2. Razer Blade Stealth 4K
Official product page and someone else's review that I found helpful.
With extra ports and a thick bezel it's not as svelte as I'd like. But the build quality seems high and I bet the 4K display looks awesome. Razer's Core external GPU is the easiest setup of its kind right now. There's also a cheaper option for $1,249 with less storage and a 2560 x 1440 screen (which is HiDPI like a MacBook but not close to 4K).
| Price | $1,599 |
| Pros | 4K display. One Thunderbolt 3 port. Charge via USB-C. |
| Cons | No USB-C ports besides the single Thunderbolt 3 one. Unnecessary video out. Big bezel around a small physical screen. |
| Thickness | 13.1mm |
| Weight | 2.84lbs |
| Battery | 53.6Wh |
| Display | 3840 x 2160 (Touch) |
| CPU | Intel 7th Generation Core i7-7500U dual core |
| RAM | 16GB |
| Storage | 512GB Flash |
| Graphics | Intel HD Graphics 620 |
| Power plug | USB-C |
| Thunderbolt 3 ports | 1 |
| USB-C (non-Thunderbolt) ports | 0 |
| USB 3.0 A ports | 2 |
| SD slots | None |
| Video ports | HDMI |
| Audio ports | Headphone/mic jack |
3. Dell XPS 13
Official product page and someone else's review that I found helpful.
This laptop has a modern edge-to-edge screen, but it's not quite 4K.
| Price | $1,849 |
| Pros | One Thunderbolt 3 / USB-C port. Nearly 4K display. |
| Cons | Expensive. Unnecessary SD card slot. |
| Thickness | 9-15mm |
| Weight | 2.9lbs |
| Battery | 60Wh |
| Display | 3200 x 1800 (Touch) |
| CPU | Intel 7th Generation Core i7-7500U dual core |
| RAM | 16GB |
| Storage | 512GB Flash |
| Graphics | Intel HD Graphics (unspecified version) |
| Power plug | Proprietary |
| Thunderbolt 3 ports | 1 |
| USB-C (non-Thunderbolt) ports | 0 |
| USB 3.0 A ports | 2 |
| SD slots | SD slot |
| Video ports | None |
| Audio ports | Headphone/mic jack |
4. HP EliteBook Folio G1
Official product page and someone else's review that I found helpful.
This machine is tiny, fanless, and looks like a MacBook Air at first glance. It has Thunderbolt 3 and none of the old ports weighting it down. And 4K! The biggest drawback is that the CPU is a 6th generation Core M processor instead of an i5 or i7. If the 12" MacBook is more your speed than the MacBook Pro, then this could be the right machine for you.
| Price | $1,799 |
| Pros | Charge via USB-C. Two Thunderbolt 3 ports. 4K display. |
| Cons | Expensive. Underpowered 6th-generation M CPU. Max 8GB of RAM. |
| Thickness | 11.93mm |
| Weight | 2.14lbs |
| Battery | 38Wh |
| Display | 3840 x 2160 |
| CPU | Intel 6th Generation m7-6Y75 dual core |
| RAM | 8GB |
| Storage | 256GB Flash |
| Graphics | Intel HD Graphics 515 |
| Power plug | USB-C |
| Thunderbolt 3 ports | 2 |
| USB-C (non-Thunderbolt) ports | 0 |
| USB 3.0 A ports | 0 |
| SD slots | None |
| Video ports | None |
| Audio ports | Headphone/mic jack |
5. Lenovo Yoga 910
Official product page and someone else's review that I found helpful.
If this had a Thunderbolt 3 port, I think it would be the laptop to get. It has a 4K screen and the styling looks great. Unfortunately, instead of Thunderbolt 3, Lenovo included a USB-C port that only speaks USB 2.0 protocol (not a typo, it's version two) and is used for charging. There's a cheaper option with less storage and RAM for $1,429.
| Price | $1,799 | Pros | Two USB-C ports. Charge via USB-C. 4K display. 2-in-1 laptop. |
| Cons | No Thunderbolt 3 ports. Small battery. Expensive. One of the USB-C ports is a USB 2.0 port. |
| Thickness | 14.3mm |
| Weight | 3.04lbs |
| Battery | 48Wh |
| Display | 3840 x 2160 (Touch) |
| CPU | Intel 7th Generation i7-7500U dual core |
| RAM | 16GB |
| Storage | 1TB Flash |
| Graphics | Intel HD Graphics 620 |
| Power plug | USB-C |
| Thunderbolt 3 ports | 0 |
| USB-C (non-Thunderbolt) ports | one 3.0 port, one 2.0 port |
| USB 3.0 A ports | 1 |
| SD slots | None |
| Video ports | None |
| Audio ports | Headphone/Microphone combined jack |
Conclusion
I'm still not sure which computer I'm going to get. I'm now looking through Linux distributions like Ubuntu and elementary OS to see what compatibility and usability are like. I doubt that 2017 will be the "year of the Linux laptop", but for the first time I'm willing to give it an honest try.
Make no mistake: I think that Apple computers are still gorgeous and a great choice for people who have the budget. I plan to continue recommending MacBooks to family members, friends, acquaintances, and all of the other non-technical people in my life. I think "it just works" is still true for the low-end, and that's ideal for consumers. But consumers have very different needs than professionals.
For a long time, Apple has been a lofty brand, the "insanely great" hardware that people bought because they aspired to "think different". It's looking like that era may be over. Apple may have completed their transition into a mass-market company that makes relatively high quality hardware for normal people. There's nothing wrong with that. But it's probably not for me.
Here's the full list of the computers I considered, in the order I ranked them:
| Model | Pros | Cons | Price |
|---|---|---|---|
| HP Spectre x360 | Two Thunderbolt 3 ports. Charge via USB-C. 2-in-1 laptop. | HD Display. | $1,299 |
| Razer Blade Stealth 4K | 4K display. One Thunderbolt 3 port. Charge via USB-C. | No USB-C ports besides the one Thunderbolt 3 one. Unnecessary video out. Big bezel. | $1,599 |
| Razer Blade Stealth QHD | HiDPI display. One Thunderbolt 3 port. Charge via USB-C. | No USB-C ports besides the one Thunderbolt 3 one. Unnecessary video out. Big bezel. | $1,249 |
| Apple MacBook Pro 13" with upgrades | Two Thunderbolt 3 ports. Charge via USB-C. HiDPI display. Good video card. | 6th generation CPU. Expensive. | $1,999 |
| Apple MacBook Pro 13" | Two Thunderbolt 3 ports. Charge via USB-C. HiDPI display. Good video card. | Underpowered i5 CPU. 6th generation CPU. Expensive. | $1,499 |
| Dell XPS 13 with upgrades | One Thunderbolt 3 / USB-C port. Nearly 4K display. | Expensive. Unnecessary SD card slot. No USB-C ports. | $1,849 |
| Dell XPS 13 | One Thunderbolt 3 / USB-C port. Nearly 4K display. | Underpowered i5 CPU. Unnecessary SD card slot. No USB-C ports. | $1,399 |
| HP EliteBook Folio G1 Notebook PC | Charge via USB-C. Two Thunderbolt 3 ports. 4K display. | Expensive. Underpowered 6th-generation M CPU. Max 8GB of RAM. | $1,799 |
| Lenovo Yoga 910 with upgrades | Two USB-C ports. Charge via USB-C. 4K display. 2-in-1 laptop. | No Thunderbolt 3 ports. Small battery. Expensive. One of the USB-C ports is a USB 2.0 port. | $1,799 |
| Lenovo Yoga 910 | Two USB-C ports. Charge via USB-C. 4K display. 2-in-1 laptop. | No Thunderbolt 3 ports. Small battery. One of the USB-C ports is a USB 2.0 port. Only 8GB of RAM. | $1,429 |
| Apple 12" MacBook | Charge via USB-C. HiDPI display. | 6th generation CPU. Poor webcam. Only one USB-C port. No Thunderbolt 3 ports. Expensive. Only 8GB of RAM. | $1,749 |
| Asus ZenBook UX306 13" | USB-C port. Nearly 4K display. | Only one USB-C port. No Thunderbolt 3 ports. Proprietary power plug. Unnecessary video out ports. 6th generation CPU. | Goes on sale any day now |
| Acer Swift 7 | Charge via USB-C. Two USB-C ports. | No Thunderbolt 3 ports. HD display. Underpowered i5 CPU. Small battery. | $1,099 |
| HP Spectre 13 | Two Thunderbolt 3 ports. Charge via USB-C. | HD Display. Only 8GB of RAM available. Small battery. | $1,249 |
| Asus ZenBook 3 UX390UA | Charging via USB-C. Very small. | HD display. Only one USB-C port. No Thunderbolt 3 ports. Expensive. Small battery. | $1,599 |
| Asus ZenBook Flip UX360CA | One USB-C port. 2-in-1 laptop. | Underpowered m3 CPU. 6th generation CPU. HD Display. No Thunderbolt 3 ports. Proprietary power plug. Unnecessary SD slot. Unnecessary video out port. | $749 |
| Microsoft Surface Book | Nearly 4K display. Surface pen included. 2-in-1 laptop. | No USB-C ports. No Thunderbolt 3 ports. Unnecessary video ports. Unnecessary SD slot. Expensive. Underpowered i5 CPU. 6th generation CPU. | $1,499 |
| Lenovo ThinkPad X1 Carbon 4th Generation 14" | HiDPI display. | No USB-C ports. No Thunderbolt 3 ports. Too many video out ports. Unnecessary SD slot. 6th generation CPU. | $1,548 |
| Samsung Notebook 9 spin | Nearly 4K display. 2-in-1 laptop. | Unnecessary SD slot. Unnecessary video out port. No USB-C ports. No Thunderbolt 3 ports. Small battery. 6th generation CPU. 8GB maximum RAM. | $1,199 |
28 October 2016
Lamenting "progress"
The new MacBook Pros were released. Many people I respect have already expressed what I'm feeling. Here's a small sample:
"I waited so long for new macbooks and now I feel like I don't want one :(" —Armin Ronacher
"<sigh> I guess I will keep the duct tape on my 2013 MBP a bit longer. The bag of dongles was not what this road warrior was looking for." —Werner Vogels
"Hi, @microsoft? Listen, I know we haven't talked for a while, and I said some... things, but... Do you want to get a coffee?" —Mark Nottingham (in reference to the Surface Studio)
My current personal machine is a 4+ year old 13" MacBook Air. I often hook it into a Thunderbolt Display, Natural Keyboard, and Magic Mouse (the one without the charging wire). The laptop is showing signs of physical wear, the battery has been losing capacity, and it's clear that I'll need a replacement soon.
When I look at the new Apple computers, my choices appear to be limited. The Touch Bar strikes me as a useless gimmick. I never look at my keyboard because I already know how to use it. I philosophically disagree with the idea of looking at your keyboard to comprehend its interface. That's not the purpose of an input device. You don't look at your mouse before you click, do you? Even if the programs I use the most (Sublime, Terminal, Chrome) integrated with the Touch Bar, I can't foresee how that would benefit me. I can only imagine that the Touch Bar's flicker during program changes would be an annoying distraction.
That means the only two Apple machines I'd consider buying are the 12" MacBook (with one USB-C port) and the 13" MacBook Pro (with the escape key and two Thunderbolt ports). The CPU, RAM, and graphics specs of these machines are essentially the same as my 2012 MacBook Air. The price is the same or higher. The ports they have provide far fewer options. The only significant improvement is that the screens are high-DPI displays. I'm disappointed.
I've been using Apple computers for nearly 30 years. I played Lunar Lander on a Mac Plus. I wrote my first Logo program on a IIgs. I dialed my first modem on a IIsi. I edited my first video on a 7100. I built my first webpage on a Performa. I wrote my first Rhapsody app on an 8600. I earned my degree on a G5. For the past 11 years as a professional programmer, I've written code on a Mac. I wrote my book on a Mac.
And now I feel that this chapter has come to an end.
For the first time, I am seriously considering not buying an Apple computer as my next machine. I can't believe it.
"I waited so long for new macbooks and now I feel like I don't want one :(" —Armin Ronacher
"<sigh> I guess I will keep the duct tape on my 2013 MBP a bit longer. The bag of dongles was not what this road warrior was looking for." —Werner Vogels
"Hi, @microsoft? Listen, I know we haven't talked for a while, and I said some... things, but... Do you want to get a coffee?" —Mark Nottingham (in reference to the Surface Studio)
My current personal machine is a 4+ year old 13" MacBook Air. I often hook it into a Thunderbolt Display, Natural Keyboard, and Magic Mouse (the one without the charging wire). The laptop is showing signs of physical wear, the battery has been losing capacity, and it's clear that I'll need a replacement soon.
When I look at the new Apple computers, my choices appear to be limited. The Touch Bar strikes me as a useless gimmick. I never look at my keyboard because I already know how to use it. I philosophically disagree with the idea of looking at your keyboard to comprehend its interface. That's not the purpose of an input device. You don't look at your mouse before you click, do you? Even if the programs I use the most (Sublime, Terminal, Chrome) integrated with the Touch Bar, I can't foresee how that would benefit me. I can only imagine that the Touch Bar's flicker during program changes would be an annoying distraction.
That means the only two Apple machines I'd consider buying are the 12" MacBook (with one USB-C port) and the 13" MacBook Pro (with the escape key and two Thunderbolt ports). The CPU, RAM, and graphics specs of these machines are essentially the same as my 2012 MacBook Air. The price is the same or higher. The ports they have provide far fewer options. The only significant improvement is that the screens are high-DPI displays. I'm disappointed.
I've been using Apple computers for nearly 30 years. I played Lunar Lander on a Mac Plus. I wrote my first Logo program on a IIgs. I dialed my first modem on a IIsi. I edited my first video on a 7100. I built my first webpage on a Performa. I wrote my first Rhapsody app on an 8600. I earned my degree on a G5. For the past 11 years as a professional programmer, I've written code on a Mac. I wrote my book on a Mac.
And now I feel that this chapter has come to an end.
For the first time, I am seriously considering not buying an Apple computer as my next machine. I can't believe it.
01 October 2016
Despite the reviews, Lo and Behold by Werner Herzog was bad: clueless questions, no narrative. He wasted his interviewees' time and mine.
30 August 2016
How you learn to become a better programmer
I received a nice email last week from a professor at a major university, who asked:
First: I'm flattered that this person thought I have any advice worth giving! My second thought was: It's impossible! But after thinking it over, I came up with one suggestion. In hopes that someone else finds my reply useful, here's what I wrote in return (with a bit more editing):
I think the best thing for improving code quality is to require your students to write a corresponding set of unittests along with any code they write. Python has a wonderful unittesting module that's built-in, as well as a good mocking library. I would encourage your students to also run a test coverage tool periodically to understand what parts of their code isn't tested.
Unittests are like an insurance policy for change. They're especially important for languages like Python that have no other way to verify correctness at even a superficial level. When your code has unittests, it becomes a lot easier to modify and expand a program over time while preserving confidence in the functionality you've already built.
Even when I write code in my free time for fun or personal projects — here's a recent example — I still write tests because they help me build functionality faster overall. The time it takes to write tests is far less than the time it takes to fix all of the bugs introduced unknowingly when you don't have tests. It's worth acknowledging that testing may feel like a waste of effort sometimes, but it's important for your students to understand that taking the time to write tests will be more efficient overall for any program that's non-trivial.
My last piece of advice is this: Sometimes people say that something was too hard to test, so they just skipped writing a test for it. This is exactly the wrong conclusion. If your code is too hard to test, that means your code is bad. The solution to every problem — no matter how hard the problem is — can be easy to test. If your program is not easy to test, then your code needs to be refactored or rewritten to make it easy. Doing that is how you learn to become a better programmer.
I'm wondering if you can share with me some advice on how to train inexperienced graduate students to be productive in writing quality code in a short period of time.
First: I'm flattered that this person thought I have any advice worth giving! My second thought was: It's impossible! But after thinking it over, I came up with one suggestion. In hopes that someone else finds my reply useful, here's what I wrote in return (with a bit more editing):
I think the best thing for improving code quality is to require your students to write a corresponding set of unittests along with any code they write. Python has a wonderful unittesting module that's built-in, as well as a good mocking library. I would encourage your students to also run a test coverage tool periodically to understand what parts of their code isn't tested.
Unittests are like an insurance policy for change. They're especially important for languages like Python that have no other way to verify correctness at even a superficial level. When your code has unittests, it becomes a lot easier to modify and expand a program over time while preserving confidence in the functionality you've already built.
Even when I write code in my free time for fun or personal projects — here's a recent example — I still write tests because they help me build functionality faster overall. The time it takes to write tests is far less than the time it takes to fix all of the bugs introduced unknowingly when you don't have tests. It's worth acknowledging that testing may feel like a waste of effort sometimes, but it's important for your students to understand that taking the time to write tests will be more efficient overall for any program that's non-trivial.
My last piece of advice is this: Sometimes people say that something was too hard to test, so they just skipped writing a test for it. This is exactly the wrong conclusion. If your code is too hard to test, that means your code is bad. The solution to every problem — no matter how hard the problem is — can be easy to test. If your program is not easy to test, then your code needs to be refactored or rewritten to make it easy. Doing that is how you learn to become a better programmer.
27 August 2016
Link roundup #7
Zero-cost futures in Rust:
Standardizing how futures / deferreds work in a language is a good idea. Python did something similar (and beyond) with asyncio and PEP 3156. JavaScript / ECMAScript 6 also defined Promises. I'm happy to see Rust do this early. I think there are some details that will make this tricky in practice since Rust doesn't have GC, so we'll see.
Google’s QUIC protocol: moving the web from TCP to UDP:
My skills are officially obsolete. I know HTTP 1.1 and TCP pretty well. I really need to understand the details of HTTP 2.0 and QUIC beyond the high-level architecture. I don't want to become a dinosaur who only knows UUCP or XNS. I've often wondered what it feels like to be an old, but still working programmer. This is probably part of it.
Working remotely:
This is a wonderful guide on how to be a thoughtful collaborator. Except for the "Before you get hired" section, almost all of the advice applies to non-remote (local?) working as well.
PyFlux:
Really cool library for working with time series in Python. See this Jupyter notebook for some compelling examples. I'm happy to see it works with Python 3 and is built on NumPy, SciPy, and Pandas.
What’s New in C# 7.0:
I surprisingly enjoyed using C# last year after ignoring it for years. It appears that the language is getting even more features with the next release. I don't think that's a good thing; some of what they're introducing seems overly complicated (e.g., out variable declarations).
Standardizing how futures / deferreds work in a language is a good idea. Python did something similar (and beyond) with asyncio and PEP 3156. JavaScript / ECMAScript 6 also defined Promises. I'm happy to see Rust do this early. I think there are some details that will make this tricky in practice since Rust doesn't have GC, so we'll see.
Google’s QUIC protocol: moving the web from TCP to UDP:
My skills are officially obsolete. I know HTTP 1.1 and TCP pretty well. I really need to understand the details of HTTP 2.0 and QUIC beyond the high-level architecture. I don't want to become a dinosaur who only knows UUCP or XNS. I've often wondered what it feels like to be an old, but still working programmer. This is probably part of it.
Working remotely:
This is a wonderful guide on how to be a thoughtful collaborator. Except for the "Before you get hired" section, almost all of the advice applies to non-remote (local?) working as well.
PyFlux:
Really cool library for working with time series in Python. See this Jupyter notebook for some compelling examples. I'm happy to see it works with Python 3 and is built on NumPy, SciPy, and Pandas.
What’s New in C# 7.0:
I surprisingly enjoyed using C# last year after ignoring it for years. It appears that the language is getting even more features with the next release. I don't think that's a good thing; some of what they're introducing seems overly complicated (e.g., out variable declarations).
06 August 2016
Link roundup #6
"With two inputs, a neuron can classify the data points in two-dimensional space into two kinds with a straight line. If you have three inputs, a neuron can classify data points in three-dimensional space into two parts with a flat plane, and so on. This is called 'dividing n-dimensional space with a hyperplane.'"
— Understanding neural networks with TensorFlow Playground
"We were looking to make usage of Kafka and Python together just as fast as using Kafka from a JVM language. That’s what led us to develop the pykafka.rdkafka module. This is a Python C extension module that wraps the highly performant librdkafka client library written by Magnus Edenhill."
— PyKafka: Fast, Pythonic Kafka, at Last!
"To satisfy this claim, we need to see a complete set of statically checkable rules and a plausible argument that a program adhering to these rules cannot exhibit memory safety bugs. Notably, languages that offer memory safety are not just claiming you can write safe programs in the language, nor that there is a static checker that finds most memory safety bugs; they are claiming that code written in that language (or the safe subset thereof) cannot exhibit memory safety bugs."
— "Safe C++ Subset" Is Vapourware
"For each mutant the tool runs the unit test suite; and if that suite fails, the mutant is said to have been killed. That's a good thing. If, on the other hand, a mutant passes the test suite, it is said to have survived. This is a bad thing."
— Mutation Testing
"This meant that literally everything was asynchronous: all file and network IO, all message passing, and any “synchronization” activities like rendezvousing with other asynchronous work. The resulting system was highly concurrent, responsive to user input, and scaled like the dickens. But as you can imagine, it also came with some fascinating challenges."
— Asynchronous Everything
— Understanding neural networks with TensorFlow Playground
"We were looking to make usage of Kafka and Python together just as fast as using Kafka from a JVM language. That’s what led us to develop the pykafka.rdkafka module. This is a Python C extension module that wraps the highly performant librdkafka client library written by Magnus Edenhill."
— PyKafka: Fast, Pythonic Kafka, at Last!
"To satisfy this claim, we need to see a complete set of statically checkable rules and a plausible argument that a program adhering to these rules cannot exhibit memory safety bugs. Notably, languages that offer memory safety are not just claiming you can write safe programs in the language, nor that there is a static checker that finds most memory safety bugs; they are claiming that code written in that language (or the safe subset thereof) cannot exhibit memory safety bugs."
— "Safe C++ Subset" Is Vapourware
"For each mutant the tool runs the unit test suite; and if that suite fails, the mutant is said to have been killed. That's a good thing. If, on the other hand, a mutant passes the test suite, it is said to have survived. This is a bad thing."
— Mutation Testing
"This meant that literally everything was asynchronous: all file and network IO, all message passing, and any “synchronization” activities like rendezvousing with other asynchronous work. The resulting system was highly concurrent, responsive to user input, and scaled like the dickens. But as you can imagine, it also came with some fascinating challenges."
— Asynchronous Everything
01 August 2016
I found this gem from 2006 that explains how the Linux kernel interacts with memory barriers. Amazingly thorough!
25 July 2016
Don't hold meetings on Mondays
A couple of months ago I stopped letting people book meetings with me on Mondays before noon. I used to get anxiety on Sunday nights because I'd worry about preparing for my meetings the next day. Now I wake up Monday, have multiple hours to better prepare for the week, and my Sundays are as lazy as they should be.
05 June 2016
Links from PyCon 2016 in Portland
Here are links for things I saw, heard about, or discovered during PyCon 2016 in Portland. These are in totally random order.
I also have a set of links from last year's PyCon as well.
- Write-ahead logging mode for SQLite 3.7, for simultaneous reads and writes
- "Tupleware outperforms [Spark, Hadoop, etc] by up to three orders of magnitude"
- "llvmlite is born of the desire to have a new Python binding to LLVM for use in Numba"
- How the built-in Enum type creates values with meta-classes
- PEP 447: "Add __getdescriptor__ method to metaclass"
- "If __new__() does not return an instance of cls, then the new instance’s __init__() method will not be invoked."
- Boltzmann machine: Machine learning with unlabelled data
- Sigmoid: "The decision function"
- Caffe: "A deep learning framework made with expression, speed, and modularity in mind"
- Anscombe's quartet: "Four datasets that have nearly identical simple statistical properties, yet appear very different when graphed"
- SPLOMs are Scatterplot matrices: "Determine if you have a linear correlation between multiple variables"
- "A sequence of random variables is Homoscedastic if all random variables in the sequence or vector have the same finite variance"
- Receiver operating characteristic: "A graphical plot that illustrates the performance of a binary classifier system"
- Scikit learn's estimator flow chart: How to choose one
- Yellowbrick: "Suite of visual analysis and diagnostic tools to facilitate feature selection, model selection, and parameter tuning for machine learning"
- "PEP8 is dead": The tool, not the PEP document; use pycodestyle instead
- Open Science Framework: "A free web app that supports project management and collaboration, connects services across the research lifecycle, and archives data, materials, and other research objects for private use or public sharing"
- Landauer bounds: "the lower theoretical limit of energy consumption of computation"
- Sparse distributed memory: "a mathematical model of human long-term memory"
- Additional unpacking syntax from PEP 448 is in Python 3.5
- Underscores in numbers will be available in Python 3.6
- A module for generating secrets will be in Python 3.6
- Larry Hastings' "GIL-ectomy" project
- Guido's King's Day speech: Also given at PyCon
- Error Prone: "A static analysis tool for Java that catches common programming mistakes at compile-time"
- Yet Another Python Formatter: "end all holy wars about formatting"
- There are differences between PyType and mypy for static analysis following PEP484
- Doug Hellmann's Smiley debugger
- Wordnik: "the world's biggest online English dictionary, by number of words"
- Fabric: "Write and execute Python functions, or tasks, to automate interactions with remote servers"
- The Seminal Kalman Filter Paper: Quickly approximating time series, used by Apollo computer
- Computational Science and Engineering: By Gilbert Strang, Professor of Math at MIT
- Falcon: "Minimal Python web framework for building microservices"
- BBC Microbit Python Guide: The board they're giving to all students in the UK
- Statistical Thinking for Data Science: Talk from SciPy 2015 conference
- MicroPython on the ESP8266: $10 board that runs Python
- NumFOCUS: The non-profit organization for NumPy, Julia, etc
- rwatch: Module to hook read accesses
- Prosaic: "Prose scraper & cut-up poetry generator"
- Use the vars() built-in function instead of accessing __dict__
- When should you prefer the format() built-in and __format__ instead of str()?
- Flake8: "Check the style and quality of some python code"
- Pandora: "A handheld game console and mobile personal computer"
- Fixed point combinator in Python
- Thespian: "Framework of an Actor model for use by applications implementing Actors"
- Documentation for Python pth files for configuring site packages
- addCleanup in the built-in unittest module
- Probabilistic Programming & Bayesian Methods for Hackers
- Statistics is Easy by Shasha & Wilson
- Resampling: The New Statistics by Julian L. Simon
I also have a set of links from last year's PyCon as well.
© 2009-2024 Brett Slatkin